1.简述
hibernate是一个开放源代码的对象关系映射框架,它对jdbc进行了轻量级的对象封装,提供hql查询语言,使得java程序员可以随心所欲的使用对象编程思维来操纵数据库。使用hibernate,必须为配置映射文件―classmapping file和configuration file,现在市场上提供了诸多hibernate代码生成工具,比如:xdoclet,以及hibernate官方自带的sechmaexport工具。然而它们都有如下的缺点:仅提供一些基本的输入模版,用户仍需要时间进行配置和修改;没有提供自动的持久类以及invokebean的代码生成;不支持图形界面;不支持对hibernatetestcase的代码生成。
hibernate工具具备以下特点:
1. 根据uml生成的数据库模型,自动生成映射文件。
2. 根据uml产生hibernate持久类。
3. hibernate模型检验。
4. 生成自动测试代码。
5. 与eclipse集成
hibernate代码生成工具采用基于powerdeigner的模型扩展功能来实现hibernate的代码生成。 powerdesigner(以下简称pd)是一款一流的数据库建模工具(e-r模型设计、物理模型设计),同时它对uml、报表、xml、团队开发(知识库repository)都支持的相当好,所有模型都可以正向、逆向的相互转换。pd的模型是由它的元模型组成。简单的说,元模型就是组成模型的模型。基于这些元模型,pd提供了一套gtl开发语言,可以轻易地扩展出自己的代码模版和流程,也可以对现有的语言模型进行修改以适应需求;pd支持利用vbscript来扩展语言、改变pd模型、模型检测。对于eclipse,pd也能做到快速的集成并可以利用java语言来修改pd模型。
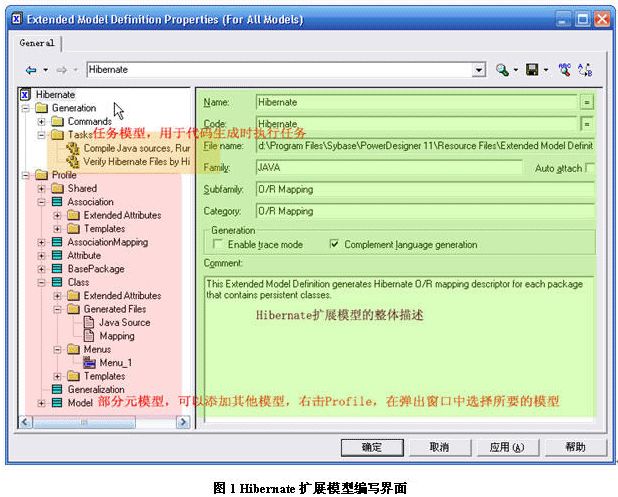
注:gtl可以说是一种面向对象的脚本语言,它可以在不同的元模型上加以扩展,增加诸如:添加生成文件、原型、菜单、代码模版、扩展属性等等功能,如图1所示,将在后续部分详细的阐述。由于元模型是面向对象的(比如所有的类、接口等的元模型都继承于classifier元模型),即如果在classifier中扩展了一个功能,那么继承它的模型均拥有这样的功能和脚本,也可以覆盖重写这样的功能,以实现多态概念。
打开扩展模型编辑窗口:选择model?extended model definition,在弹出的窗口的toolbar上选择import extended model definition(倒数第二个按钮)来加载已有的模型,也可以新建扩展模型(选择add row按钮,然后在表格中双击要编辑的模型的第一列即可弹出如图1所示的界面)
点击查看大图
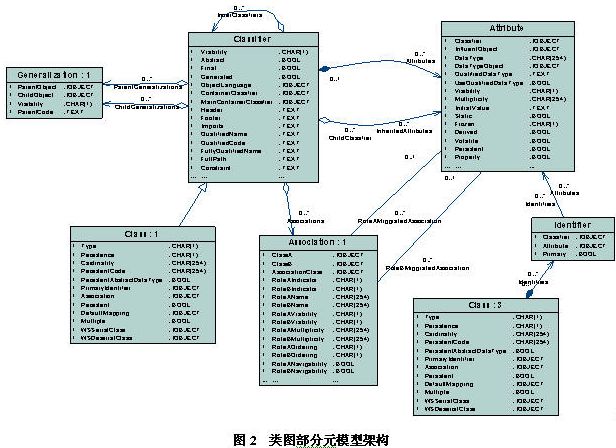
为了让读者更好的了解pd的元模型概念,截取了hibernate代码生成工具所用到的元模型架构图,如图2所示。 读者可以在pd的安装目录下找到:<pd安装路径>/examples/metamodel.oom,图表存放在pdoom下,名字为class objects。
由于篇幅原因,会摘取典型的代码和模型来讲解如何设计hibernate代码生成工具。
点击查看大图
hibernate代码生成的总体架构流程(活动图)
hibernate自动生成文件的原则是:
1) 子类的映射信息挂在根类的映射文件下(root class),即子类将不独立生成代码
2) value-type类以及没有持久化的类,将不生成代码。
3) 不为非类对象生成代码(比如接口等)
其中:
check models in diagram: hibernate模型检测,判断domainmodel是否符合hibernate语法。如果出错,pd将抛出错误提示信息(提供自动纠错的功能)
generate configuration file:选择模型属性(model->model properties),用户可以在extended attribute下设置配置信息,pd会根据配置信息生成configuration file。
get each class in diagram:这是pd的机制,它会自动获取uml内的所有模型元素,并根据每个模型的扩展属性(profile/generated file)的流程来生成代码文件。
generate basic mapping:类的基本映射,它包含id,composite-id,propery等。
get subclass style:子类的映射,递归获取。
generate join:当持久类对应于多张表的映射时,需要用join来指明。
generate association mapping:根据类之间association的类型来判断是哪种关连映射,本工具支持one-to-one,one-to-many,many-to-one,many-to-many(根据association properties的detail标签下的multiplicity来设置),支持集合array,set,list,bag,idbag(根据containtype来设置)。
get java code information:扩展模型是基于现有的语言模型,即扩展模型能够获取语言模型的模版和各种设置,对于hibernate的java持久类,我们只须在java代码下增加对应attribute的getter和setter即可。%source%
generate invoke bean: 生成hibernate的crud函数。
generate test case: hibernate测试用例代码,将生成的随机数据来验证hibernate的正确性。
generate log4j: 生成log4j的配置文件
generate ant build.xml: 当用户在generation files下的options中设置ant为true,并配置了ant的lib的路径,则hibernate tools会生成build.xml, 然后将会自动运行ant来测试hibernate, 生成结果将会被log4j存入日志。 2.技术要点
o/r mapping
pd从8.0开始,就不断加强o/r mapping,除了代码模型的生成以外,pd也生成o/r mapping的定义,诸如生成ejb cmp组件。用户可以定义o/r mapping来建立oom与pdm之间的关系。
pd支持3种方式的o/r mapping:
第一种是从类图转换成数据模型之后由pd自动建立连接(适用于自顶向下的设计过程);
第二种是从数据模型转换成类图之后由pd自动建立连接(适用于自下向上的设计过程);
第三种是建立类图和数据模型之后由用户手动建立(适用于同步设计或者是后期的修改)
建立过程:
第一种:选择类图,然后设计持久类(pojo),完毕之后,选择tools->generate physical data model。在弹出的窗口中,选择detail标签,选中o/r mapping选项,即可。读者可以选择是更新现有的数据库还是新建数据库。
第二种:与第一种建立过程相似,只是换成在数据库模型中选择generate object-oriented model
第三种:用户必须首先建立datasource,在左边workspace树形目录下找到类文件,然后右击选择new/data source,在弹出的窗口的models标签中选择 ,并选择想与之关联的数据库模型。在类模型中打开类属性(双击要建立o/r mapping的类),选择mapping选项卡,点击 按钮添加刚才建立的datasource。然后点击 添加类映射的数据表,即建立完毕。
用户可以添加多张表,它表示一个类可能对应多张表的映射,hibernate的映射则应该用join属性来指明。
注:当用户建立了classsource,pd会根据类的属性和表的字段自动建立attributemapping,当然用户也可以在attributemapping属性页下对其映射进行修改。
大家知道,hibernate的映射文件必须包含对表的表述(比如:column,property属性等等),在pd中,通过元模型中的mapping可以轻易地获取对应的表信息。图4是gtl中用到的o/r mapping元模型。
o/r mapping架构图:
点击查看大图
架构说明:
1) association:
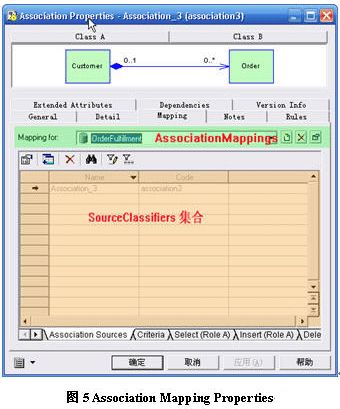
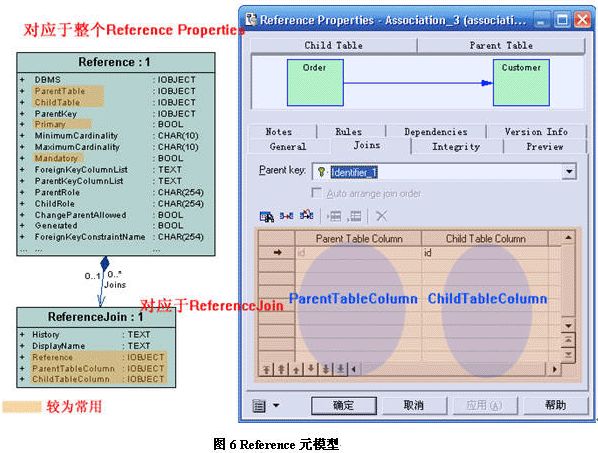
在asoociation元模型中,可以通过mappings来获取associationmapping(即用户在mapping for下选择的datasource),每个associationmapping都会有sourceclassifiers,它是asoociationsource标签内的映射集合,如图5所示。sourceclassifiers集合中的元素,也就是数据模型中的reference元模型,如图6所示。
由于pd可以在association mapping下添加数据模型中的其他reference和table,所以在做hibernate代码生成时,采用了类型判断,以避免因类型不匹配而造成的错误。
点击查看大图
?实现代码(表映射):(注:附录部分将介绍部分gtl语法)
.点击查看大图
?实现代码(referencecolumnhelper模版):
点击查看大图
2) class和attribute
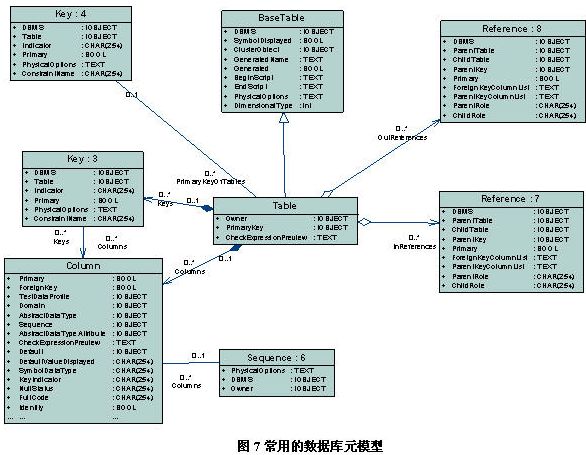
获取数据库模型的方法与association类似,在o/r mapping中,classmapping的sourcefeature等价于数据表; attributemapping的sourcefeature等价于数据表中的列信息。图7给出了在编写过程中使用到的数据库元模型的架构图。
?实现代码(获取类对应的表信息)
点击查看大图
说明:mappings.first.classsources表明当前data source下的表集合
?实现代码(获取attribute对应的列信息)
例如:%attributemappings.first.sourcefeature.code%
%attributemappings.first.sourcefeature%对应于图7的column元模型。
extended attribute
hibernate生成工具中对于映射文件,难免要遇到大量的选项让用户选择或者输入,这时,我们就可以利用pd提供的extended attribute来扩展模型的属性。对于uml模型,除了dependency和generalization,其余模型均有extended attribute来扩展。
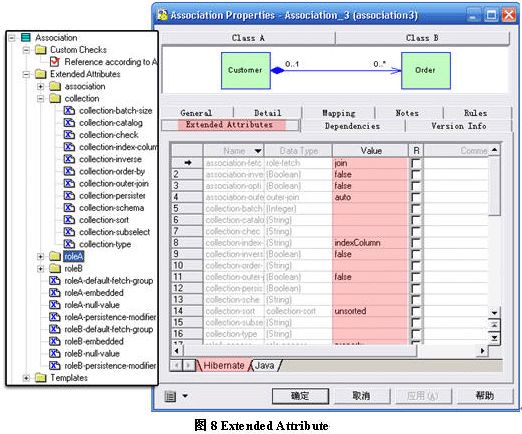
设置extended attribute步骤:进入扩展模型编辑窗口,在profile下选择一个元模型,然后右键选择extended attribute, pd已提供了多种默认的选项(加括号的),当然用户增加自己的extended attribute type(在profile下的shared目录上按右键选择extended attribute type,然后在右边可以设置列项内容以及默认值等等。设置完之后读者就可以在模型的扩展属性中引用到自定义的类型),如图8所示。在gtl中,可以用%属性名%引用到当前用户的选择值,也可以用%模版名%引用到gtl模版(读者可以选择模版并按f12跳转)。
check model
考虑,由于基于uml建立的domainmodel,对于hibernate语法来说,难免有一些语法上的错误,比如:在两个类之间建立association,但对应的表之间却没有reference,或者是有reference却没有joins下的column,这时我们应该给出一个错误警告,提示用户检查。
以刚才提到的associationcheck为例,将介绍如何实现用户自定义的check。
打开hibernate扩展模型,选中profile/association,右击选中new/custom check。在右边,读者可以看到有四个选项卡,如图9所示。
check script: 用于检测模型,%check%=true, 将不出现错误信息。
autofix script: 用于自动修复模型错误,%fix%=false, 表示不修复该错误。当pd监测到错误时,用户可以在错误上右键选择automatic correction即可。对于自动修复的错误,会在图标右下角加上一个”+”号,如 ,表示pd以根据autofix script修复完成。
global script: 用于存放全局函数,在任何元模型的check model均可调用。
实现代码
check script: 用于检测refence的建立正确与否。
点击查看大图
注:pd会对每个模型进行检测(包括package),所以如果读者希望通过程序来控制该模型是否被检测,只须在满足条件的语法段内加上%check% = true (表示验证正确并跳过)即可。
persistent class持久类
对于pojo的持久类,必须为其每个类的属性增加getter和setter函数。扩展模型是基于语言模型之上的,也就是说,语言模型中的模板等内容均可在扩展模型中覆盖和重写。所以,在hibernate扩展模型中采用重载的方法,扩展了java语言模型的代码生成,保留了原先java那部分代码,并在扩展模型中加上自己的getter和setter模版。
在java语言模型中,代码生成是依靠%source%模版来完成java代码的,同时有一个%initializers%模版实现当完成attribute之后的一些初始化工作,所以在相同位置(class元模型)的地方重写了%initializers%模版,代码如下:
点击查看大图
在attribute元模型中增加getterfunction 、setterfunction模版,代码如下:
点击查看大图
然后在class元模型中增加持久类的generated files,并在模版编辑框内输入%source%即可。
generated files
pd在每个元模型中提供了文件生成的功能。在class元模型上右键选择generated files。在右边窗口中,在 file name 下输入生成后的文件名。由于hibernate映射文件的文件名与类名相同,故输入%mappingfilename%,同时建立mappingfilename 模版,并输入%code%.hbm.xml。
注:所有的元模型都继承于namedobject(namedobject继承于baseobject),在namedobject中存放了各种元模型的标准属性,比如:模型名称(name)、代码名称(code)、注释、描述等等。所以,为了取到类的名称,就在类元模型下输入%code%.hbm.xml,那么pd会根据代码名称为每个类建立相应的文件(前提是该类可以被生成,即已持久化)。
model
model元模型中主要实现对configuration mapping的连接信息的配置,诸如,jdbc等。所用到的方法也就是extended attribute和mapping代码模版。由于篇幅原因,不一一列举,读者可以参考刚才所讲,或者可以在pd安装目录下运行pdvbs11.chm来获取帮助。
task
task在代码生成完毕之后被激活,然后pd会依次序执行选中的任务。扩展了hibernate模型,增加了ant的lib路径,生成的目录名称等等选项。在generation/ options下建立新的选项即可,类似于extended attribute。调用options选项时,输入如下代码:%genoptions.选项名% 即可获取。
对于task,希望能够借助ant的build.xml配置进行自动测试。在pd中,java语言模型已经提供了ant的build.xml的自动生成并预留接口 (customexecutetarget、customerproperties、customtaskdefs三个模版) ,目的为了能让扩展模型来重载,有兴趣的读者可以查看java语言模型(language?edit current object language,浏览java::profile/model/templates/ant/anttemplate)。
建立task:
在generation/tasks上右键,选择new。输入task name(就是真正执行的显示名),取名为run unit test。在下面的表格中选择已建立的command,如果没有建立,则可以在commands上新建。
run unit test command代码:
点击查看大图
说明:
.execute_command为宏命令,用于执行外部的程序。
.execute_command '(' <cmd> [',' <args> [',' <mode>]] ')'
第一个参数为主命令,这里是cmd
第二个参数为主命令的参数,这里是/k ant.bat junit
第二个参数为管道类型,pd提供cmd_shellexecute和cmd_pipeoutput两种方式。前者采用独立的进程方式,后者将会阻塞pd直到任务完成,并且结果将显示在pd的output窗口内,如图10所示。
点击查看大图
3.结束语
powerdesigner是一款灵活性非常强的软件建模工具,基于它的元模型,读者可以随心所欲的用不同语言 (gtl, vbscript, java, c#等) 来设计出自己的代码生成工具,甚至是语言模型、报表等等。本篇仅仅起到了一个抛砖引玉的作用,我相信,凭借着领域中的经验,读者一定也可以设计出更适合自己的代码生成工具,简化流程、降低成本、加快开发。
附录:
列举了gtl的部分语法,读者也可以参阅pd安装目录下的pdvbs11.chm文件或者sybase官方网站。
1. 资源文件
读者可以参考pd11的现有模型:
您可以在安装目录下/ resource files/extended model definitions找到现有的扩展模型;在安装目录下/ vb scripts找到vbscript代码;ole automation目录下找到如何用java,c#等其他语言来获取元模型来做自己的代码生成工具;library目录下找到语言模型。在printable docs目录下找到pdf文档(建议参考advanced user documentation.pdf文档)。
2. 语法
a. 设置变量
点击查看大图
变量名必须用%来封装,即%变量名%
全局变量
点击查看大图
变量区域
简单的说,当区域建立后(比如,循环,另一个模版等),在区域中调用区域外的变量,则需要用outer.变量名来指明。
b. 循环
点击查看大图
c. 判断条件
点击查看大图
d. 集合
点击查看大图
e. 特殊符号
点击查看大图
hibernate是一个开放源代码的对象关系映射框架,它对jdbc进行了轻量级的对象封装,提供hql查询语言,使得java程序员可以随心所欲的使用对象编程思维来操纵数据库。使用hibernate,必须为配置映射文件―classmapping file和configuration file,现在市场上提供了诸多hibernate代码生成工具,比如:xdoclet,以及hibernate官方自带的sechmaexport工具。然而它们都有如下的缺点:仅提供一些基本的输入模版,用户仍需要时间进行配置和修改;没有提供自动的持久类以及invokebean的代码生成;不支持图形界面;不支持对hibernatetestcase的代码生成。
hibernate工具具备以下特点:
1. 根据uml生成的数据库模型,自动生成映射文件。
2. 根据uml产生hibernate持久类。
3. hibernate模型检验。
4. 生成自动测试代码。
5. 与eclipse集成
hibernate代码生成工具采用基于powerdeigner的模型扩展功能来实现hibernate的代码生成。 powerdesigner(以下简称pd)是一款一流的数据库建模工具(e-r模型设计、物理模型设计),同时它对uml、报表、xml、团队开发(知识库repository)都支持的相当好,所有模型都可以正向、逆向的相互转换。pd的模型是由它的元模型组成。简单的说,元模型就是组成模型的模型。基于这些元模型,pd提供了一套gtl开发语言,可以轻易地扩展出自己的代码模版和流程,也可以对现有的语言模型进行修改以适应需求;pd支持利用vbscript来扩展语言、改变pd模型、模型检测。对于eclipse,pd也能做到快速的集成并可以利用java语言来修改pd模型。
注:gtl可以说是一种面向对象的脚本语言,它可以在不同的元模型上加以扩展,增加诸如:添加生成文件、原型、菜单、代码模版、扩展属性等等功能,如图1所示,将在后续部分详细的阐述。由于元模型是面向对象的(比如所有的类、接口等的元模型都继承于classifier元模型),即如果在classifier中扩展了一个功能,那么继承它的模型均拥有这样的功能和脚本,也可以覆盖重写这样的功能,以实现多态概念。
打开扩展模型编辑窗口:选择model?extended model definition,在弹出的窗口的toolbar上选择import extended model definition(倒数第二个按钮)来加载已有的模型,也可以新建扩展模型(选择add row按钮,然后在表格中双击要编辑的模型的第一列即可弹出如图1所示的界面)
为了让读者更好的了解pd的元模型概念,截取了hibernate代码生成工具所用到的元模型架构图,如图2所示。 读者可以在pd的安装目录下找到:<pd安装路径>/examples/metamodel.oom,图表存放在pdoom下,名字为class objects。
由于篇幅原因,会摘取典型的代码和模型来讲解如何设计hibernate代码生成工具。
hibernate代码生成的总体架构流程(活动图)
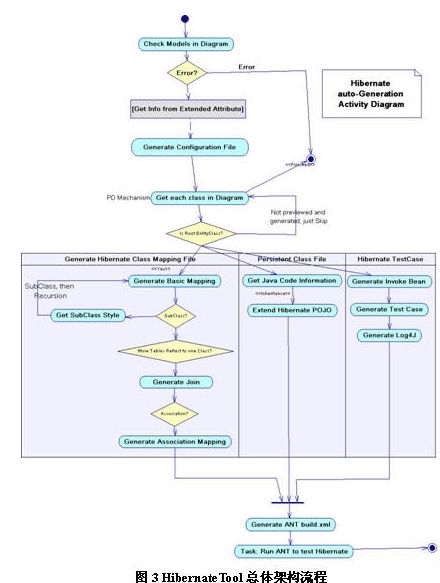
hibernate自动生成文件的原则是:
1) 子类的映射信息挂在根类的映射文件下(root class),即子类将不独立生成代码
2) value-type类以及没有持久化的类,将不生成代码。
3) 不为非类对象生成代码(比如接口等)
其中:
check models in diagram: hibernate模型检测,判断domainmodel是否符合hibernate语法。如果出错,pd将抛出错误提示信息(提供自动纠错的功能)
generate configuration file:选择模型属性(model->model properties),用户可以在extended attribute下设置配置信息,pd会根据配置信息生成configuration file。
get each class in diagram:这是pd的机制,它会自动获取uml内的所有模型元素,并根据每个模型的扩展属性(profile/generated file)的流程来生成代码文件。
generate basic mapping:类的基本映射,它包含id,composite-id,propery等。
get subclass style:子类的映射,递归获取。
generate join:当持久类对应于多张表的映射时,需要用join来指明。
generate association mapping:根据类之间association的类型来判断是哪种关连映射,本工具支持one-to-one,one-to-many,many-to-one,many-to-many(根据association properties的detail标签下的multiplicity来设置),支持集合array,set,list,bag,idbag(根据containtype来设置)。
get java code information:扩展模型是基于现有的语言模型,即扩展模型能够获取语言模型的模版和各种设置,对于hibernate的java持久类,我们只须在java代码下增加对应attribute的getter和setter即可。%source%
generate invoke bean: 生成hibernate的crud函数。
generate test case: hibernate测试用例代码,将生成的随机数据来验证hibernate的正确性。
generate log4j: 生成log4j的配置文件
generate ant build.xml: 当用户在generation files下的options中设置ant为true,并配置了ant的lib的路径,则hibernate tools会生成build.xml, 然后将会自动运行ant来测试hibernate, 生成结果将会被log4j存入日志。 2.技术要点
o/r mapping
pd从8.0开始,就不断加强o/r mapping,除了代码模型的生成以外,pd也生成o/r mapping的定义,诸如生成ejb cmp组件。用户可以定义o/r mapping来建立oom与pdm之间的关系。
pd支持3种方式的o/r mapping:
第一种是从类图转换成数据模型之后由pd自动建立连接(适用于自顶向下的设计过程);
第二种是从数据模型转换成类图之后由pd自动建立连接(适用于自下向上的设计过程);
第三种是建立类图和数据模型之后由用户手动建立(适用于同步设计或者是后期的修改)
建立过程:
第一种:选择类图,然后设计持久类(pojo),完毕之后,选择tools->generate physical data model。在弹出的窗口中,选择detail标签,选中o/r mapping选项,即可。读者可以选择是更新现有的数据库还是新建数据库。
第二种:与第一种建立过程相似,只是换成在数据库模型中选择generate object-oriented model
第三种:用户必须首先建立datasource,在左边workspace树形目录下找到类文件,然后右击选择new/data source,在弹出的窗口的models标签中选择 ,并选择想与之关联的数据库模型。在类模型中打开类属性(双击要建立o/r mapping的类),选择mapping选项卡,点击 按钮添加刚才建立的datasource。然后点击 添加类映射的数据表,即建立完毕。
用户可以添加多张表,它表示一个类可能对应多张表的映射,hibernate的映射则应该用join属性来指明。
注:当用户建立了classsource,pd会根据类的属性和表的字段自动建立attributemapping,当然用户也可以在attributemapping属性页下对其映射进行修改。
大家知道,hibernate的映射文件必须包含对表的表述(比如:column,property属性等等),在pd中,通过元模型中的mapping可以轻易地获取对应的表信息。图4是gtl中用到的o/r mapping元模型。
o/r mapping架构图:
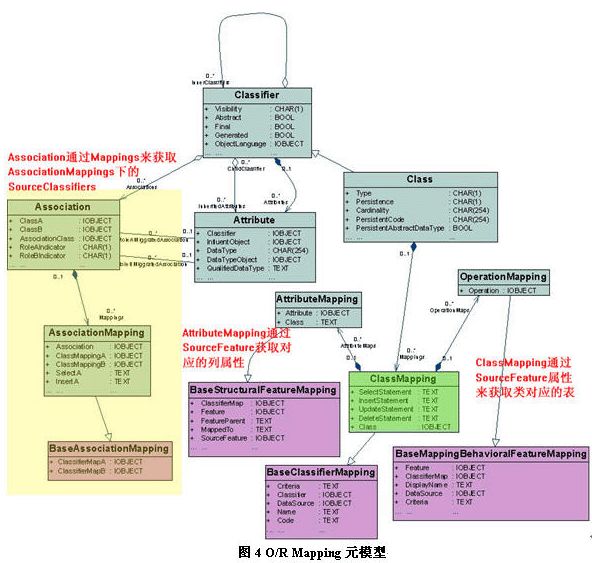
架构说明:
1) association:
在asoociation元模型中,可以通过mappings来获取associationmapping(即用户在mapping for下选择的datasource),每个associationmapping都会有sourceclassifiers,它是asoociationsource标签内的映射集合,如图5所示。sourceclassifiers集合中的元素,也就是数据模型中的reference元模型,如图6所示。
由于pd可以在association mapping下添加数据模型中的其他reference和table,所以在做hibernate代码生成时,采用了类型判断,以避免因类型不匹配而造成的错误。
?实现代码(表映射):(注:附录部分将介绍部分gtl语法)
.

?实现代码(referencecolumnhelper模版):

2) class和attribute
获取数据库模型的方法与association类似,在o/r mapping中,classmapping的sourcefeature等价于数据表; attributemapping的sourcefeature等价于数据表中的列信息。图7给出了在编写过程中使用到的数据库元模型的架构图。
?实现代码(获取类对应的表信息)

说明:mappings.first.classsources表明当前data source下的表集合
?实现代码(获取attribute对应的列信息)
例如:%attributemappings.first.sourcefeature.code%
%attributemappings.first.sourcefeature%对应于图7的column元模型。
extended attribute
hibernate生成工具中对于映射文件,难免要遇到大量的选项让用户选择或者输入,这时,我们就可以利用pd提供的extended attribute来扩展模型的属性。对于uml模型,除了dependency和generalization,其余模型均有extended attribute来扩展。
设置extended attribute步骤:进入扩展模型编辑窗口,在profile下选择一个元模型,然后右键选择extended attribute, pd已提供了多种默认的选项(加括号的),当然用户增加自己的extended attribute type(在profile下的shared目录上按右键选择extended attribute type,然后在右边可以设置列项内容以及默认值等等。设置完之后读者就可以在模型的扩展属性中引用到自定义的类型),如图8所示。在gtl中,可以用%属性名%引用到当前用户的选择值,也可以用%模版名%引用到gtl模版(读者可以选择模版并按f12跳转)。
check model
考虑,由于基于uml建立的domainmodel,对于hibernate语法来说,难免有一些语法上的错误,比如:在两个类之间建立association,但对应的表之间却没有reference,或者是有reference却没有joins下的column,这时我们应该给出一个错误警告,提示用户检查。
以刚才提到的associationcheck为例,将介绍如何实现用户自定义的check。
打开hibernate扩展模型,选中profile/association,右击选中new/custom check。在右边,读者可以看到有四个选项卡,如图9所示。

check script: 用于检测模型,%check%=true, 将不出现错误信息。
autofix script: 用于自动修复模型错误,%fix%=false, 表示不修复该错误。当pd监测到错误时,用户可以在错误上右键选择automatic correction即可。对于自动修复的错误,会在图标右下角加上一个”+”号,如 ,表示pd以根据autofix script修复完成。
global script: 用于存放全局函数,在任何元模型的check model均可调用。
实现代码
check script: 用于检测refence的建立正确与否。

注:pd会对每个模型进行检测(包括package),所以如果读者希望通过程序来控制该模型是否被检测,只须在满足条件的语法段内加上%check% = true (表示验证正确并跳过)即可。
persistent class持久类
对于pojo的持久类,必须为其每个类的属性增加getter和setter函数。扩展模型是基于语言模型之上的,也就是说,语言模型中的模板等内容均可在扩展模型中覆盖和重写。所以,在hibernate扩展模型中采用重载的方法,扩展了java语言模型的代码生成,保留了原先java那部分代码,并在扩展模型中加上自己的getter和setter模版。
在java语言模型中,代码生成是依靠%source%模版来完成java代码的,同时有一个%initializers%模版实现当完成attribute之后的一些初始化工作,所以在相同位置(class元模型)的地方重写了%initializers%模版,代码如下:

在attribute元模型中增加getterfunction 、setterfunction模版,代码如下:

然后在class元模型中增加持久类的generated files,并在模版编辑框内输入%source%即可。
generated files
pd在每个元模型中提供了文件生成的功能。在class元模型上右键选择generated files。在右边窗口中,在 file name 下输入生成后的文件名。由于hibernate映射文件的文件名与类名相同,故输入%mappingfilename%,同时建立mappingfilename 模版,并输入%code%.hbm.xml。
注:所有的元模型都继承于namedobject(namedobject继承于baseobject),在namedobject中存放了各种元模型的标准属性,比如:模型名称(name)、代码名称(code)、注释、描述等等。所以,为了取到类的名称,就在类元模型下输入%code%.hbm.xml,那么pd会根据代码名称为每个类建立相应的文件(前提是该类可以被生成,即已持久化)。
model
model元模型中主要实现对configuration mapping的连接信息的配置,诸如,jdbc等。所用到的方法也就是extended attribute和mapping代码模版。由于篇幅原因,不一一列举,读者可以参考刚才所讲,或者可以在pd安装目录下运行pdvbs11.chm来获取帮助。
task
task在代码生成完毕之后被激活,然后pd会依次序执行选中的任务。扩展了hibernate模型,增加了ant的lib路径,生成的目录名称等等选项。在generation/ options下建立新的选项即可,类似于extended attribute。调用options选项时,输入如下代码:%genoptions.选项名% 即可获取。
对于task,希望能够借助ant的build.xml配置进行自动测试。在pd中,java语言模型已经提供了ant的build.xml的自动生成并预留接口 (customexecutetarget、customerproperties、customtaskdefs三个模版) ,目的为了能让扩展模型来重载,有兴趣的读者可以查看java语言模型(language?edit current object language,浏览java::profile/model/templates/ant/anttemplate)。
建立task:
在generation/tasks上右键,选择new。输入task name(就是真正执行的显示名),取名为run unit test。在下面的表格中选择已建立的command,如果没有建立,则可以在commands上新建。
run unit test command代码:

说明:
.execute_command为宏命令,用于执行外部的程序。
.execute_command '(' <cmd> [',' <args> [',' <mode>]] ')'
第一个参数为主命令,这里是cmd
第二个参数为主命令的参数,这里是/k ant.bat junit
第二个参数为管道类型,pd提供cmd_shellexecute和cmd_pipeoutput两种方式。前者采用独立的进程方式,后者将会阻塞pd直到任务完成,并且结果将显示在pd的output窗口内,如图10所示。
powerdesigner是一款灵活性非常强的软件建模工具,基于它的元模型,读者可以随心所欲的用不同语言 (gtl, vbscript, java, c#等) 来设计出自己的代码生成工具,甚至是语言模型、报表等等。本篇仅仅起到了一个抛砖引玉的作用,我相信,凭借着领域中的经验,读者一定也可以设计出更适合自己的代码生成工具,简化流程、降低成本、加快开发。
附录:
列举了gtl的部分语法,读者也可以参阅pd安装目录下的pdvbs11.chm文件或者sybase官方网站。
1. 资源文件
读者可以参考pd11的现有模型:
您可以在安装目录下/ resource files/extended model definitions找到现有的扩展模型;在安装目录下/ vb scripts找到vbscript代码;ole automation目录下找到如何用java,c#等其他语言来获取元模型来做自己的代码生成工具;library目录下找到语言模型。在printable docs目录下找到pdf文档(建议参考advanced user documentation.pdf文档)。
2. 语法
a. 设置变量

变量名必须用%来封装,即%变量名%
全局变量

变量区域
简单的说,当区域建立后(比如,循环,另一个模版等),在区域中调用区域外的变量,则需要用outer.变量名来指明。
b. 循环

c. 判断条件

d. 集合

e. 特殊符号


 闽公网安备 35060202000074号
闽公网安备 35060202000074号