持久化对于大部分企业应用来说都是至关重要的,因为它们需要访问关系数据库,尽管有不少选择可以用来来构建应用程序的持久化层,但是并没有一个统一的标准可以用在java ee环境和java se环境中。在这篇文章中,笔者将会使用一个简单的对象模型作为例子来介绍ejb3 java 持久化 api。
持久化对于大部分企业应用来说都是至关重要的,因为它们需要访问关系数据库,例如oracle database 10g。如果你正使用java开发应用程序,你可能会负责一些很乏味的工作,例如使用jdbc和sql来编写更新或者读取数据库的代码。在过去的几年中,一些对象-关系映射框架,例如oracle toplink和jboss hibernate,已经非常流行了,因为它们简化了持久化操作,将java开发人员从无聊琐碎的jdbc代码中解放出来,使他们可以更加关注业务逻辑。一些java标准,例如ejb2.x中的容器管理持久化的实体bean也试图解决持久化问题,但是它们的努力显得不是很成功。
尽管有不少选择可以用来来构建应用程序的持久化层,但是并没有一个统一的标准可以用在java ee环境和java se环境中。ejb3java持久化api为我们带来了好消息,作为ejb 3.0规范(jsr-220)中的一部分,它标准化了java平台下的持久化api。jsr-220已经被o-r mapping软件生产商广泛支持,例如toplink 和 hibernate,同时它还被一些应用服务器生产商和jdo生产商所支持。ejb3规范为java企业应用构建持久化层提供了一个强制性的选择。
在这篇文章中,笔者将会使用一个简单的对象模型作为例子来介绍ejb3 java 持久化 api。
领域模型
当你构建一个企业应用时,你首先设计需要持久化到数据库中的领域模型。然后,你需要和数据库设计人员一起设计好数据库结构。领域模型是持久化对象或者实体的代表。一个实体可以是一个人,一个地方,或者任何其他你想要存储的数据。它同时包含了数据和行为。一个rich领域模型具有所有的oo的特征,例如继承和多态(inheritance and polymorphism)。
我们作为示例使用的这个简单的领域模型如下,部门(department)和雇员(employee)实体之间具有双向的一对多关系,而全职员工(fulltime)和承包工(contractor)实体都是从雇员实体继承而来。
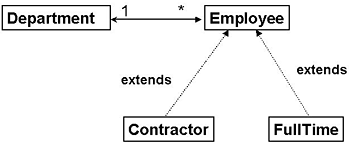
图 1. 示例领域对象模型
o-r映射框架和ejb3 jpa的基础
如果你使用过oracle toplink这样的o-r映射框架构建过应用程序的持久化层,那么你会注意到每个持久化框架都会提供3种机制
1. 声明性的o-r 映射方法。这种方法,叫做o-r映射元数据,使得你可以将一个对象映射到数据库中的一个或者多个表。大部分的o-r映射框架都使用xml来存储o-r映射的元数据。
2. 用来操作实体的api(例如,来执行crud操作)。api让你用来持久化,获取,更新或者删除对象。基于o-r映射元数据和api的使用,o-r映射框架代替你来完成各种数据库操作。api将你从繁琐的jdbc和sql代码中解救出来。
3. 一种查询语言来获取对象。这是持久化操作的很重要的一个方面,因为不合适的sql语句会使得你的数据库操作变慢。这种查询语言避免了在应用程序中混杂大量sql语句的现象。
ejb3 java 持久化api标准化了java平台下的持久化操作,它提供一种标准的o-r映射机制,一组entitymanager api来进行crud操作,以及一种扩展的ejb-ql语言来获取实体。笔者将在分别讨论这3个方面。
元数据标注
java se 5.0 引入了元数据标注。java ee的所有组件,包括 ejb3 jpa,都大量使用了元数据标注来简化企业java应用的开发。想要了解更多的元数据标注方面的知识,请参阅kyle downey 写的bridging the gap: j2se 5.0 annotations文章。在ejb3 jpa中,元数据可以用来定义对象,关系,o-r映射以及持久化上下文(context)的注入。jpa同样提供了使用xml描述符来提供持久化元数据的方法。而笔者则会重点讲述使用标注的方式,因为这使得开发变得更加简单。但是,在产品部署阶段,你或许会倾向于使用xml描述符,你可以使用xml描述符来覆盖标注定义的持久化行为。
在jpa中将o-r映射标准化
定义持久化对象:实体
一个实体是一个轻量级的领域对象?d?d一个需要持久化到关系数据库中的pojo。与其他的pojo一样,一个实体可以是抽象类或者具体类,而且它可以从其他pojo扩展得到。可以使用javax.persistence.entity标注将一个pojo标注成一个实体
下面是如何将领域模型中的department对象变成一个实体的例子:
| package onjava; import java.io.serializable; import java.util.collection; import javax.persistence.*; @entity @namedquery(name="findalldepartment", query="select o from department o") @table(name="dept") public class department implements serializable { @id @column(nullable=false) protected long deptno; @column(name="dname") protected string name; @column(name="loc") protected string location; @onetomany(mappedby="department") protected collection<employee> employees; public department() { } ... public collection<employee> getemployees() { return employees; } public void setemployees(collection<employee> employees) { this.employees = employees; } public employee addemployee(employee employee) { getemployees().add(employee); employee.setdepartment(this); return employee; } public employee removeemployee(employee employee) { getemployees().remove(employee); employee.setdepartment(null); return employee; } } |
每一个实体都有一个主键;可以在一个持久化字段(field)或者属性上使用id标注来将它作为一个主键。一个实体可以通过使用字段或者属性(通过 setter and getter 方法)来维护自己的状态。这取决于你在何处使用id标注。上面的例子中采用了基于字段的访问,我们在deptno字段上使用了id标注。如果要使用基于属性的访问,你需要在属性上使用id这样的标注。
| @id public long getdeptno() { return deptno; } public void setdeptno(long deptno) { this.deptno = deptno; } |
必须注意,在一个实体继承体系中的所有实体,都必须使用通用的访问类型,或者都使用字段,或者都使用属性。
一个实体中定义的所有字段,默认情况下,都会进行持久化。如果你不想存储某个字段(或者属性),你必须将字段(或者属性)定义成临时的,通过采用@transient标注或者采用transient修饰符。
嵌入对象
一个嵌入对象是一个自己不具有id的持久化对象。它是另外一个实体的一部分。例如,我们可以假定address对象没有自己的id,并且它作为employee实体的一部分进行存储。因此,address是一个嵌入对象。
你可以采用如下的方法来创建一个嵌入对象
| @embeddable public class address { protected string streetaddr1; protected string streetaddr2; protected string city; protected string state; .. } |
下面是如何将一个对象嵌入到一个目标对象中
| @entity public class employee { @id @generatedvalue(strategy=generationtype.auto) protected long id; ... @embedded protected address address; ... } |
关系
在一个典型的领域模型中,实体可能互相联系或者存在一定的关系。两个实体之间的关系可能是一对一(one-to-one),一对多(one-to-many),多对一(many-to-one),多对多(many-to-many)。实体之间的这些关系可以分别使用onetoone, onetomany, manytoone, or manytomany标注来描述。我们的示例在department和employee实体上采用了双向的onetomany关系。
既然我们在实体中使用了基于字段的访问,那么我们就在department实体的关系字段上使用标注,如下:
| @onetomany(mappedby="department") protected collection<employee> employees ; |
对于一个双向的关系来说,你必须指定mappedby元素,就像上面那样,通过指明拥有这个关系的字段名或者属性名来指出反向的关系如何进行映射。
标准化o-r 映射
你可以使用java标注或者xml来进行实体的o-r映射的定义。ejb3 jpa定义了几个标注来进行o-r映射,例如table,secondarytable, column, joincolumn, 以及 primarykeyjoincolumn等标注。参考ejb3 jpa规范来获取所有标注的信息。
在我们的例子中,你可以使用table标注来定义该实体应该映射到那个表中,例如:
| @table(name="dept") public class department implements serializable { |
ejb3 jpa中,各种映射都普遍具有默认值。如果你不定义表映射的话,持久化提供者会假定这个实体将要映射到和实体类类名同名的表中(在这个例子中就是deparment表)。如果你的实体需要映射到多个表中,你可以使用secondarytable标注。
你可以使用column标注将一个字段或者属性映射到数据库中的一个字段,就像下面这样:
| @column(name="dname") protected string name; |
这里,dname是需要持久化的字段name要映射的数据库中的字段名。如果你不使用column定义字段的映射的话,持久化引擎会尝试使用与字段名或者属性名相同的数据库字段名来进行持久化。
实体继承
ejb3 jpa 采用多种方法来支持实体继承。它需要两种类型的继承表映射策略:single-table-per-entity 继承层次策略和joined-subclass策略。最好避免使用可选的table-per-class层次。
single-table-per-entity 继承层次策略允许一个继承层次中的所有实体都映射到单一的表中。在我们的示例中,fulltime和contractor都继承了employee,所有它们的示例都会被映射到一个叫做emp的表中。换句话说,所有与employee,fulltime和contractor相关的数据都会被存储到同一个表中。
如果你使用joined-subclass策略,你可以将通用的数据映射到超类(例如employee)表中,同时为每个子类定义一个表来存储子类特有的数据。
必须在超类上使用inheritance标注来指明采用的继承映射策略,就像下面的代码那样。这个例子演示了实体继承层次使用single-table-per-entity策略的方法。
| @entity @table(name="emp") @inheritance(strategy=inheritancetype.single_table) @discriminatorcolumn(name="employee_type", discriminatortype=discriminatortype.string, length=1) public abstract class employee implements serializable { ... } |
每个子类必须指明用于区分实体类型的值,如下所示:
| @entity @discriminatorvalue(value="f") public class fulltime extends employee { @column(name="sal") protected double salary; @column(name="comm") protected double commission; @column(name="desig") protected string designation; ... } |
entity manager api:实体操作的标准api
javax.persistence.entitymanager 用来管理实体的声明周期,它提供了几个方法来进行实体的crud操作。
entitymanager api 在一个事务上下文(transaction context)中被调用。你可以从ejb容器以外来调用它,例如,你可以从一个web应用中来调用,使用entitymanager api并不一定需要一个sesssion bean门面(facade).
在你进行实体操作之前,你必须获取一个entitymanager的实例。你可以使用容器管理的实体管理器,也可以使用应用程序管理的实体管理器,同时你可以使用jndi查询或者依赖注射来获取entitymanager得实例。顾名思义,在容器管理的entity manager的情况下,java ee容器管理entity manager的生命周期。这通常在企业java应用中使用。
你可以使用persistencecontext标注来进行依赖注射而获取一个容器管理的entity manager的实例,如下:
| @persistencecontext(unitname="onjava") private entitymanager em; |
如果你想要使用应用程序管理的entity manager,你必须自己管理它的声明周期。你可以使用如下方法创建它的一个实例。
| @persistenceunit(unitname="onjava") private entitymanagerfactory emf; private entitymanager em = emf.createentitymanager(); |
然后,就可以使用entitymanager实例来进行实体的crud操作了。为了关闭应用程序管理的entity manager的实例,在进行完操作以后调用em.close()方法。
就像前面提到的,一个包含了任何数据库改变的entity manager的操作都必须在一个事务上下文中进行。
下面的表列出了entitymanager接口的一些重要方法,这些方法用于进行实体操作。
| 方法 | 目的 |
| public void persist(object entity); | 持久化一个实体的实例 |
| public |
合并一个detached实体 |
| public void remove(object entity); | 删除实体的实例 |
| public |
通过主键获取实体的实例 |
| public void flush(); | 将实体的状态与数据库同步 |
可以使用persist()方法来持久化一个实体的实例。例如,如果想要持久化contractor的一个实例,使用以下的代码:
| @persistencecontext(unitname="onjava") private entitymanager em; ... contractor pte = new contractor(); pte.setname("nistha") pte.sethourlyrate(new double(100.0)); em.persist(pte); |
如果持久化了一个实体,并且实体上的关系的cascadetype被设置为persist或者是all的话,那么任何和该实体关联的实体的状态变化都会被持久化。除非你使用一个扩展的持久化上下文,否则的话,实体在事务结束以后就会变成detached状态。merge操作允许你使用一个持久化上下文将一个detached实体存储到数据库中,这个detached实体的状态将会和数据库同步。这可以使你摆脱在ejb 2.x 时代普遍使用的dto这种反模式,因为现在实体都是pojo,可以在各个层之间传递。对于实体类的唯一要求就是要实现java.io.serializable接口。
查询api
持久化的另一个重要问题就是实体的获取。当使用ejb3 jpa时,查询使用java 持久化查询语言来表达。jpql是ejb ql(ejb2.0中引入)的一个扩展。但是,ejb3 jpa,解决了ejb ql的一些限制并且增加了新的功能,使之成为一个强大的查询语言。
jpql对于ejbql 2.x的增强
以下是jpql的一些新功能:
- ---简化的查询语法
- ---连接操作
- ---group by 和 having 语句
- ---子查询
- ---动态查询
- ---命名参数
- ---批量更新和删除
而且,你可以使用native sql来查询实体如果你需要特定的数据库查询扩展的话。
动态查询 vs. 命名查询
你可以使用动态查询或者命名查询。一个命名查询和实体存储在一起,并且可以在程序中重复使用。
为了创建一个动态查询,使用entity manager接口的createquery方法,如下:
| query query = em.createquery( "select e from employee e where e.empno > ?1"); query.setparameter(1,100); return query.getresultlist(); |
如果想要使用命名查询来进行这个查询,在实体类中使用namedquery标注,如下:
| @entity @namedquery(name="findallemployee", query="select e from employee e where e.empno > ?1") public abstract class employee implements serializable { } |
为了执行一个命名查询,首先使用entitymanager接口的createnamedquery方法来创建一个query实例,如下:
| query = em.createnamedquery(" findallemployee"); query.setparameter(1,100); return query.getresultlist(); |
命名参数
你可以在ejbql中使用命名参数来代替位置参数,例如,你可以使用如下方法来改写上面的查询:
| "select e from employee e where e.empno > :empno " |
如果在查询中使用命名参数,你必须使用如下的方法来设置参数:
| query = em.createnamedquery("findallemployee"); query.setparameter("empno",100); return query.getresultlist(); |
打包
ejb3 jpa标准化了pojo的持久化操作。因此,实体并不限于ejb模块,它们可以打包在一个web模块中,一个ejb-jar模块,ear级别的类模块,或者一个标准的jar文件中。你也可以在j2se环境中使用实体。你必须将一个部署描述符文件(在persistence.xml)打包进去。
| <persistence> <persistence-unit name="onjava"> <provider>oracle.toplink.essentials.persistenceprovider</provider> <jta-data-source>jdbc/oracleds</jta-data-source> ... </persistence-unit> </persistence> |
这个部署描述符确定了持久化提供者,持久化单元以及持久化单元使用的数据源。顾名思义,一个持久化单元就是需要一起管理的一组实体。如果你在一个特定的模块中定义了唯一一个持久化单元,你就不需要在persistence.xml中定义实体类,持久化提供者会自动找到实体类。
toplink essentials:参考实现
toplink essentials,是从主要的一个商业o-r映射框架oracle toplink中衍生出来的,这是ejb3 jpa的一个参考实现。可以从java persistence api implementation home page找到它。
你可以在一个该参考实现的服务器或者其他的遵循ejb3 jpa固定的应用服务器上使用本文中的代码。
ejb3 jpa工具
开发工具确实能够帮助你创建更好的应用程序――并且如果你使用xml来定义o-r映射,操作会很繁琐。eclipse dali o-r映射项目致力于使得ejb3 jpa变得更加简单,它在eclipse web工具项目中提供了综合的工具,这个项目是oracle领导的,并且被jboss,bea以及versant所支持。想要了解更多关于dali的信息请访问它的主页。
同样的,oracle jdeveloper 10.1.3和bea workshop studio这样的工具也支持ejb3 jpa。
结论
ejb3 java持久化api标准化了java平台的持久化操作。它通过使用元数据标注简化了透明持久化操作。几个应用服务器,包括oracle application server 10g (10.1.3), sun公司的开源的 glassfish application server, and jboss application server 4.0, 都提供了ejb3 规范的支持。当java ee5.0和ejb 3.0最终确定下来,你可以很快看到很多领先的应用服务器和持久化提供者都实现了ejb3 java persistence api。你可以使用glassfish项目提供的参考实现来开始ejb3的持久化的使用。
版权声明:techtarget获matrix授权发布,如需转载请联系matrix
作者:debu panda;shenpipi
原文:http://www.onjava.com/pub/a/onjava/2006/05/17/standardizing-with-ejb3-java-persistence-api.html
matrix:http://www.matrix.org.cn/resource/article/44/44549_ejb3.html

 闽公网安备 35060202000074号
闽公网安备 35060202000074号