项目团队已经很熟悉如何组织一些具体的任务并完成他们。简单的性能问题很容易由一个开发人员分离并解决。然而大的性能问题,通常在系统处于高负载情况下发生,就不是这么简单能处理的了。这些问题需要一个独立的测试环境、一个模拟的负载,并且需要仔细地分析和跟踪。
在这篇文章中,我使用比较通用的工具和设备创建了一个测试环境。我会专注于两个性能问题,内存和同步,他们很难用简单的分析得到。通过一个具体的例子,我希望比较容易地解决复杂的性能问题而且可以提供处理问题过程中的细节。
改善服务器的性能
服务器的性能改善是依赖于数据的。没有可靠的数据基础而更改应用或环境会导致更差的结果。分析器提供有用的java服务器应用信息,但由于从单用户负载下的数据与多用户负载下得到的数据是完全不同的,这导致分析器的数据并不精确。在开发阶段使用分析器来优化应用的性能是一个好的方式,但在高负载下的应用分析可以取到更好的效果。
在负载下分析服务器应用的性能需要一些基本的元素:
1、可控的进行应用负载测试的环境。
2、可控的人造负载使得应用满负荷运行。
3、来自监视器、应用和负载测试工具自身的数据搜集。
4、性能改变的跟踪。
不要低估最后一个需求(性能跟踪)的重要性因为如果不能跟踪性能你就不能实际的管理项目。性能上10-20%的改善对单用户环境来说并没有什么不同,但对支持人员来说就不一样了。20%的改善是非常大的,而且通过跟踪性能的改善,你可以提供重要的反馈和持续跟踪。
虽然性能跟踪很重要,但有时为了使后续的测试更加精确而不得不抛弃先前的测试结果。在性能测试中,改善负载测试的精确性可能需要修改模拟环境,而这些变化是必须的,通过变化前后的负载测试你可以观察到其中的转变。
可控的环境
可控的环境最少也需要两台独立的机器和第三台控制的机器。其中一台用来生成负载,另一台作为控制机与前一台建立测试应用并接受反馈,第三台机器运行应用。此外,负载和应用机器间的网络应该与局域网分开。控制机接受运行应用机器的反馈如操作系统、硬件使用率、应用(特别是vm)的状态。
负载模拟
最精确的模拟通常用实际的用户数据和web服务器端的访问日志。如果你还没有实际布署或者缺少实际的用户数据,你可以通过构造类似的场景或询问销售和产品管理团队或做一些有依据的猜想。协调负载测试和实际用户体验是一个持续的过程。
在模拟中一些用户场景是必须的。如在一个通用地址薄应用中,你应该区分更新和查询操作。在我的测试应用中grinderservlet类只有一个场景。单用户连接10次访问这个servlet(在每一次访问间有一段暂停)。虽然这个应用很小,我认为这可以重复一些常见的东西。用户通常不会连接给服务器请求而没有间断。如果没有间断,我们可能不能得到更精确的实际用户上限。
串行10个请求的另一个原因是实际应用中不会只有一个http请求。单一而又分离的请求可以影响环境中的许多因素。对tomcat来说,会为每一个请求创建一个会话,并且http协议允许不同的请求重用连接。我会修改一下负载测试来避免混洧。
grinderservlet类不会执行任何排序操作,但这个需求在大部分应用中都很普通。在这些应用中,你需要创建模拟的数据集并且用他们来构造相关用例的负载测试。
例如,如果用例涉及到用户登录一个web应用,从可能的用户列表中选取随机的用户会只使用一个用户更精确。否则,你可能不经意地使用了系统缓存或其他的优化或一些微妙的东西,而这会使得结果不正确。
负载测试软件
负载测试软件可以构造测试场景并且对服务进行负载测试。我会在下面的示例中使用opensta测试软件。这软件简单易学,结果也很容易导出,并且支持参数化脚本,还可以监视信息的变化,他的主要缺点是基于windows,但在这儿不是个问题。当然还有很多可选项如apache的jmeter和mercury的loadrunner。
the grinderservlet
列表1中显示了grinderservlet类,列表2中显示了grinder类
listing 1
package pub.capart;import java.io.*;
import java.util.*;
import javax.servlet.*;
import javax.servlet.http.*;
public class grindservlet extends httpservlet {
protected void doget(httpservletrequest req, httpservletresponse res)
throws servletexception, ioexception {
grinderv1 grinder = grinderv1.getgrinder();
long t1 = system.currenttimemillis();
grinder.grindcpu(13);
long t2 = system.currenttimemillis();
printwriter pw = res.getwriter();
pw.print("<html>/n< body> /n");
pw.print("grind time = "+(t2-t1));
pw.print("< body> /n< /html> /n");
}}
listing 2
package pub.capart;
/*** this is a simple class designed to simulate an application consuming* cpu, memory, and contending for a synchronization lock.*/public class grinderv1 { private static grinderv1 singleton = new grinderv1(); private static final string randstr =
"this is just a random string that i'm going to add up many many times";
public static grinderv1 getgrinder() {
return singleton;
} public synchronized void grindcpu(int level) {
stringbuffer sb = new stringbuffer();
string s = randstr;
for (int i=0;i<level;++i) {
sb.append(s);
s = getreverse(sb.tostring());
}
}
public string getreverse(string s) {
stringbuffer sb = new stringbuffer(s);
sb = sb.reverse();
return sb.tostring();
}}
类很简单,但他们会产生两个很常见的问题。咋一看瓶颈可能由grindcpu()方法的同步修饰符引起,但实际上内存消耗才是真正的问题所在。如图1,我的第一个负载测试显示了常见的负载变化。在这里负载变化很重要因为你正在模拟一个高的负载。这种热身的方式也更精确因为避免了jsp编译引起的问题。我通常习惯于在进行负载测试前先进行单用户模拟。
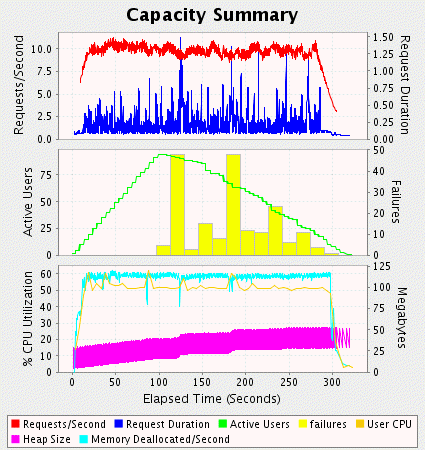
figure 1
我在这篇文章中会使用相同的容量小结图。在执行负载测试时还有更多的可用信息,但这里只用了有用的部分。最上面的面板包含每秒完成的请求数和请求时间信息。第二个面板包含活动用户数和失败率,我将超时、不正确的服务器应答和长于5秒的请求认为是失败的。第三个面板包含jvm内存统计和cpu使用率。cpu值是所有处理器的用户时间的平均值,这里所有的测试机器都是双cpu的。内存统计图包含垃圾回收表和每秒垃圾回收数。
图1中两个最明显的数据是50%的cpu使用率和大量内存使用和释放。从列表2中可以看出这个原因。同步修饰符导致所有进程串行处理,就好像只用了一个cpu,而算法导致大量内存消耗在局部变量上。
通过cpu是个受限的资源,如果在这个测试中我可以完全利用到两个cpu的话就可以提高一倍的性能。垃圾回收器运行得如此频繁以致于不能忽略。在测试中每秒释放的内存达到100m,很显然这是个限制因素。失败数这么大明显这个应用是不可用的。
监视
在生成合理的用户负载后,监视工具需要收集进程的运行状况。在我的测试环境中可以收集到各种有用的信息:
1、 所有计算机、网络设备
2、 等等的使用率
3、 jvm的统计数据。
4、 个别java方法所花费的时间。
5、 数据库性能信息,6、 包括sql查询的统计。
7、 其他应用相关的信息
当然这些监视也会影响负载测试,但如果影响比较小也可以忽略。基本上如果我们想获取所有上面的信息,肯定会影响测试的性能。但如果不是一次获取所有信息还是有可能保证负载测试的有效性。仅对特定的方法设置定时器,仅获取低负载的硬件信息和低频率地获取样例数据。当然不加载监视器来做测试是最好的,然后和加载监视器的测试来做比较。虽然有时候侵入式监视是个好主意,但就不可能有监视结果了。
获取所有监视数据到一个中央控制器来做分析是最好的,但使用动态运行时工具也可以提供有用的信息。例如,命令行工具如ps、top、vmstat可以提供unix机器的信息;性能监视器工具可以提供windows机器的信息;而teamquest, bmc patrol, sgi's performance co-pilot, and ism's perfman这样的工具会在所有的测试环境中的机器安装代理并且将需要的信息传回中央控制机,这样就可以提供文本或可视化的信息。在本文中,我使用开源的performance co-pilot作为测试统计的工具。我发现他对测试环境的影响最小,并且以相对直接的方式来提供数据。
java分析器提供很多信息,但通常对负载测试来说影响太大而没有太多的用处。工具甚至可以让你在负载服务器上做一些分析,但这也很容易便测试无效。在这些测试中,我激活了详细的垃圾收集器来收集内存信息。我也使用jconsole 和jstack工具(包含在j2se 1.5中)来检查高负载下的vm。我没有保留这些测试用例中负载测试的结果因为我认为这些数据不是很正确。
同步瓶颈
在诊断服务器问题时线程的信息是非常有用的,特别是对同步之类的问题。jstack工具可以连接到运行的进程并且保存每一个线程的堆栈信息。在unix系统可以用信号量3来保存线程的堆栈信息,在windows系统的控制台中可以用ctrl-break。在第一项测试中,jstack指出许多线程在grindcpu()方法中被阻塞。
你可以已经注意到列表2中grindcpu()方法的同步修饰符实际上并不必须。我在后一项测试中删除了他,如图2显示
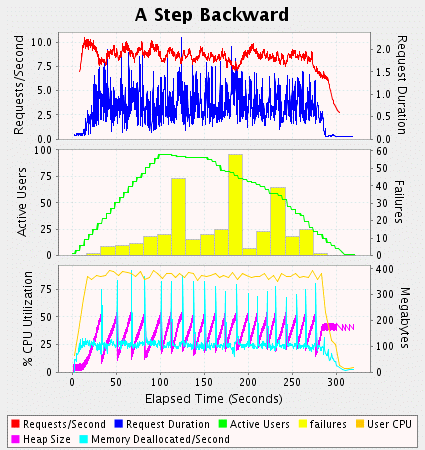
figure 2
在图2中,你会注意到性能下降了。虽然我使用了更多的cpu,但吞吐量和失败数都更差了。虽然垃圾回收周期变了,但每秒依然需要回收100m。显然我们还没有找到主要的瓶颈。
非竟争的同步相对于简单的函数调用还是很费时的。竟争性的同步就更费时了,因为除了内存需要同步外,vm还需要维护等待的线程。在这种状况下,这些代价实际上要小于内存瓶颈。实际上,通过消除了同步瓶颈,vm内存系统承担了更多的压力最后导致更差的吞吐量,即使我使用了更多的cpu。显然最好的方式是从最大的瓶颈开始,但有时这也不是很容易确定的。当然,确保vm的内存处理足够正常也是一个好的开始方向。
内存瓶颈
现在我会首先也定位内存问题。列表3是grinderservlet的重构版本,使用了stringbuffer实例。图3显示了测试结果。
listing 3
package pub.capart;
/*** this is a simple class designed to simulate an application consuming* cpu, memory, and contending for a synchronization lock.*/public class grinderv2 {
private static grinderv2 singleton = new grinderv2();
private static final string randstr =
"this is just a random string that i'm going to add up many many times";
private stringbuffer sbuf = new stringbuffer();
private stringbuffer sbufrev = new stringbuffer();
public static grinderv2 getgrinder() {
return singleton;
}
public synchronized void grindcpu(int level) {
sbufrev.setlength(0);
sbufrev.append(randstr);
sbuf.setlength(0);
for (int i=0;i<level;++i) {
sbuf.append(sbufrev);
reverse();
}
return sbuf.tostring();
}
public string getreverse(string s) {
stringbuffer sb = new stringbuffer(s);
sb = sb.reverse();
return sb.tostring(); }}
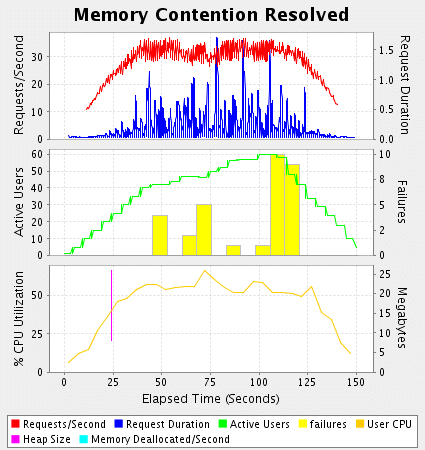
figure 3
通常重用stringbuffer并不是一个好主意,但这里我只是为了重现一些常见的问题,而不量提供解决方案。内存数据已经从图上消失了因为测试中没有垃圾回收器运行。吞吐量戏剧性的增加而cpu使用率又回到了50%。列表3不只是优化了内存,但我认为主要了改善了过度的内存消耗。
检视同步瓶颈
列表4另一个grinderservlet类的重构版本,实现了一个小的资源池。图4显示了测试结果。
listing 4
package pub.capart;/*** this is just a dummy class designed to simulate a process consuming* cpu, memory, and contending for a synchronization lock.*/public class grinderv3 {
private static grinderv3 grinders[];
private static int grinderroundrobin = 0;
private static final string randstr =
"this is just a random string that i'm going to add up many many times";
private stringbuffer sbuf = new stringbuffer();
private stringbuffer sbufrev = new stringbuffer();
static {
grinders = new grinderv3[10];
for (int i=0;i<grinders.length;++i) {
grinders[i] = new grinderv3();
}
}
public synchronized static grinderv3 getgrinder() {
grinderv3 g = grinders[grinderroundrobin];
grinderroundrobin = (grinderroundrobin +1) % grinders.length;
return g;
}
public synchronized void grindcpu(int level) {
sbufrev.setlength(0);
sbufrev.append(randstr);
sbuf.setlength(0);
for (int i=0;i<level;++i) {
sbuf.append(sbufrev);
reverse();
}
return sbuf.tostring();
}
public string getreverse(string s) {
stringbuffer sb = new stringbuffer(s);
sb = sb.reverse();
return sb.tostring(); }}
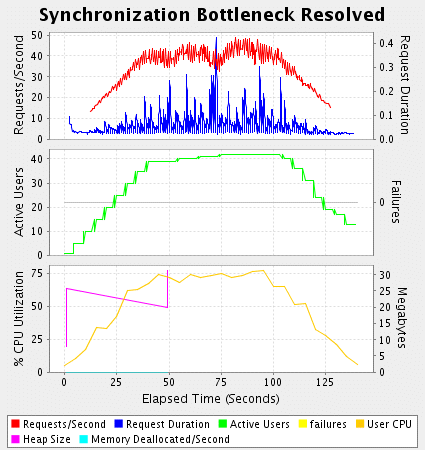
figure 4
吞吐量有一定的增加,而且使用更少的cpu资源。竟争和非竟争性同步都是费时的,但通常最大的同步消耗是减少了系统的可伸缩性。我的负载测试不再满足系统的需求了,因此我增加了虚拟的用户数,如图5 所示。
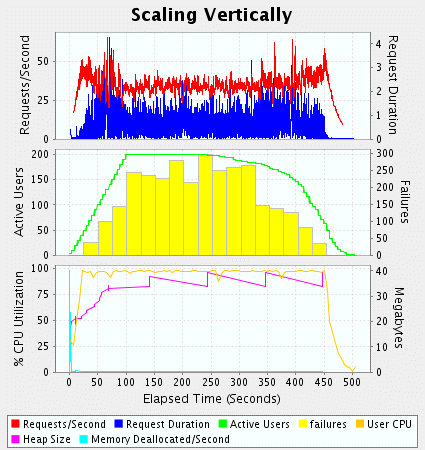
figure 5
在图5 中吞吐量在负载达到饱和时下降了一些然后在负载减少时又提高了。此外注意到测试使得cpu使用率达到100%,这意味着测试超过了系统的最佳吞吐量。负载测试的一个产出是性能计划,当应用的负载超过他的容量时会产生更低的吞吐量。
水平可伸缩性
水平伸缩允许更大的性能,但并不一定是费用相关的。运行在多个服务器上的应用通常比较运行在单个vm上的应用复杂。但水平伸缩支持在性能上的最大增加。
图6是我的最后一项测试的结果。我已经在三台基本一致的机器上使用了负载平衡,只是在内存和cpu速度上稍有不同。总的吞吐量要高于三倍的单机结果,而且cpu从来没有完全利用。在图6中我只显示了一台机器上的cpu结果,其他的是一样的。
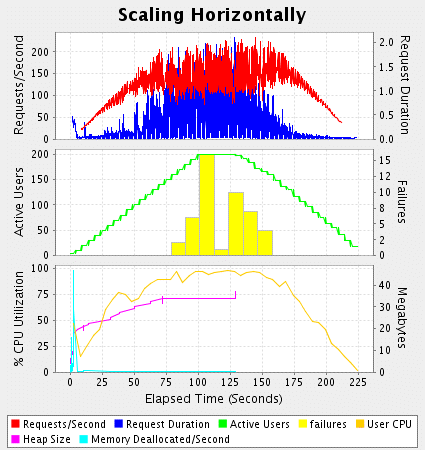
figure 6
小结
我曾经花了9个月来布署一个复杂的java应用,但却没有时间来做性能计划。但差劲的性能使得用户合约几乎中止。开发人员使用分析器花了很长时间找到几个小问题但没有解决根本的瓶颈,而且被后续的问题完全迷惑了。最后通过负载测试找到解决方法,但你可以想到其中的处境。
又一次我碰得更难的问题,应用只能达到所预期性能的1/100。但通过前期检测到的问题和认识到负载测试的必要性,这个问题很快被解决了。负载测试相对于整个软件开发的花费并不多,但其所归避的风险就高多了。

 闽公网安备 35060202000074号
闽公网安备 35060202000074号