自从核心java语言的第一个公开发行版本起,jdbc(java数据库连接)已经经历了十年的发展历程。它的当前版本4.0(将与java标准版本6.0一起打包发行)提供了一组更为丰富的api,主要目的在于改进软件开发的设计和性能。
本文将重点讨论jdbc 4.0规范在设计和性能方面的改进。
一、 注释和泛型dataset
在本文中,我假定你已经了解注释和泛型。其实,这两个概念是随着j2se 5.0的发行一同引入的;与此同时,jdbc 4.0中引入了注释和泛型dataset。这一变化的主要目的是为了简化sql查询和sql dml(数据操纵语言)语句的执行。
新一代api定义了一组query和dataset接口。这个query接口定义了一组带有jdbc注释的方法。这些带有注释的方法描述了sql select和update语句,并且指定应该如何把结果绑定到一个dataset上。这个dataset接口是一个通过泛型定义实现的参数化类型,也为结果集数据提供一种类型安全的定义。
所有的query接口都继承自basequery接口。你可以使用connection.createqueryobject()或datasource.createqueryobject()方法(这两个方法都使用一个query接口类型作为它的参数)来具体实现这样的接口。
一个dataset接口继承自java.util.list;该接口使用一个描述结果集数据列的数据库(该数据库是通过query接口的一个注释的方法返回的)作为它的参数类型。在连接方式和非连接方式下都可以操作和使用dataset。因此,根据使用的是连接方式还是非连接方式,这个dataset也分别相应地实现为一个resultset或cachedrowset。dataset,作为java.util.list的一个子接口,允许使用iterator模式通过java.util.iterator接口存取其数据行。
你可以用两种方式来指定数据类或用户定义类(作为dataset接口的一个参数类型)-作为一个结构或作为一个javabeans对象。无论哪一种方式都能够把结果集数据列绑定到用户定义的类定义上;但是,javabeans组件模型更漂亮些,并且更利于对象定义在另外的支持javabeans模型的框架中的重用。
列表1摘自本文示例中的代码片断,它展示了如何使用这种新型的api来创建和运行sql查询:使用一个用户定义类定义结果集数据,并且把返回的结果集绑定到用户定义的描述中。
列表1.employee用户定义类型与employeequeries接口
| pubic class employee { private int employeeid; private string firstname; private string lastname; public int getemployeeid() { return employeeid; } public setemployeeid(int employeeid) { this.employeeid = employeeid; } public string getfirstname() { return firstname; } public setfirstname(string firstname) { this.firstname = firstname; } public string getlastname() { return lastname; } public setlastname(string lastname) { this.lastname = lastname; } } interface employeequeries extends basequery { @select (sql="select employeeid, firstname, lastname from employee") dataset<employee> getallemployees (); @update (sql="delete from employee") int deleteallemployees (); } connection con = ... employeequeries empqueries = con.createqueryobject (employeequeries.class); dataset<employee> empdata = empqueries.getallemployees (); |
二、 改进异常处理能力
在jdbc api 4.0以前的版本中,异常处理功能极其有限。对于所有类型的错误都会笼统地抛出一个sqlexception异常-根本不存在异常的详细分类,且没有相应的层次定义。所以这时,你唯一能够得到一些有意义的信息的办法是检索和分析sqlstate值。另一方面,sqlstate值及其相应的含义会因不同的数据源而有所改变;因此,要想追踪到问题的"根部"并且有效地处理异常是一件非常乏味的任务。
jdbc 4.0改进了异常处理能力,同时也缓解了一些前面提到的问题。其中的关键改进有:
? 把sqlexception分成短暂异常和非短暂异常两种类型
? 支持链式异常
? 实现iterable接口
当一个以前失败的操作检索成功时,将会抛出sqltransientexception异常;而在检索不成功时将会抛出sqlnontransientexception异常-除非导致sqlexception的原因得到纠正。
图1展示了子类sqltransientexception和sqlnontransientexception。
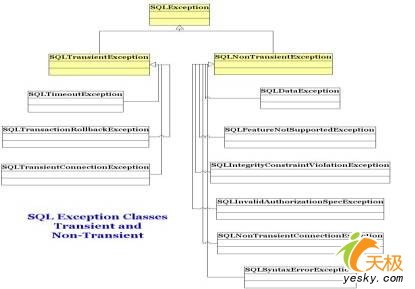 图1.sql异常类型:短暂型和非短暂型 |
另一方面,在新的api中,加入了对链式异常的支持。新的异常基类构造器中添加了额外参数以捕获异常的可能原因。例如,在一个循环中可能存在sqlexception遍历;这时,开发人员可以调用getcause()来决定异常的可能原因。如果获取的结果的确是产生这些异常的原因,那么getcause()方法能够返回一个非sqlexception。
现在,sqlexception类实现了iterable接口并且支持j2se 5.0的for each循环。
列表2描述了新的for-each-loop结构的用法:
列表2.for each循环结构
| catch(sqlexception ex) { for(throwable t : ex) { system.out.println("exception:" + t); } } |
三、 支持xml数据类型
如今,大量的数据行以xml格式存在。通过在sql 2003规范中定义了一种标准xml类型,现在大多数数据库都已提供对xml数据类型的支持。通过加入这样一种数据类型,一个xml数据集或文档可能成为一个数据库表中的一行的一个字段或列值。在jdbc 4.0以前,也许在jdbc框架内操作这样的数据的最好的方法是使用来自于驱动程序供应商的专利扩展产品或作为一种clob类型来存取它。
现在,jdbc 4.0把sqlxml定义为映射数据库sql xml类型的java数据类型。这种api支持把一个xml类型作为一个字符串或作为一个stax流进行处理。streaming api for xml(在jsr 173规范中确立)基于iterator模式,它与基于observer模式的simple api for xml processing(sax)形成对照。
调用connection对象的createsqlxml()方法就能够创建一个sqlxml对象。开始时这是一个空对象;因此,通过使用setstring()方法或createxmlstreamwriter()方法把一个xml流关联到该对象可以把数据依附到其上。同样,xml数据可以从一个sqlxml对象中进行检索,这是通过使用getstring()或createxmlstreamreader()方法把一个xml流与该对象关联实现的。
resultset,preparedstatement和callablestatement接口中都提供了getsqlxml()方法用于检索sqlxml数据类型。另外,preparedstatement和callablestatement中还引入了setsqlxml()方法用于把sqlxml对象作为参数添加。
当对象在长时间运行的事务中保持有效时,可以通过调用上面这些接口的free()方法来释放sqlxml资源;事实证明这是一种比较适当的方法。另外,开发者可以在一个数据源上调用databasemetadata的gettypeinfo()方法来检查数据库是否支持sqlxml数据类型,因为这个方法能够返回它支持的所有数据类型。
四、 改进connection接口
connection接口定义也得到了增强,用于更高效地分析连接状态。
有时数据库连接是不可用的,尽管可能不必关闭这些连接并对之进行垃圾回收。处于这样的情况下,数据库常常表现出速度缓慢且不具有响应性。此时,在大多数情况下,重新初始化该连接也许是解决这种问题的唯一方法。在jdbc 4.0以前版本时,没有办法来区分一个旧连接和一个已经关闭的连接;而新式api则在connection接口中添加了一个isvalid()方法用来查询是否连接仍然有效。
另外,数据库连接经常在客户端被共享;并且有时,一些客户使用的资源比另一些客户多,这可能会导致一种"饥饿"现象。为此,connection接口中定义了一个setclientinfo()方法以定义客户端特定的属性,这可以被客户端用于分析和监控资源利用情况。
五、 有关rowid方面的改进
在许多数据库中,rowid都被用作唯一标识一个表中行的方法。在查询条件中使用rowid往往是检索数据的最快方法,特别是在oracle和db2数据库情况下。现在,既然java.sql.rowid是一种内嵌的java类型;那么,你就可以充分利用与其用法相关的性能优点。当表中存在重复的数据并且一些行数据相同时,rowid是标识唯一行的最有效的方法。然而,还要注意到,rowid在一个表中是唯一的,而对于整个数据库来说并非如此;它们可能发生变化并且不为所有数据库所支持。典型情况下,rowid不是跨数据源可移植的;因此,当使用多种数据源时应该慎重。
在数据源定义的生命周期内,只要一行未被删除,那么该行相应的rowid就一直保持有效。我们可以调用databasemetadata.getrowidlifetime()方法来决定rowid的生命周期。这个方法的返回类型是一个枚举类型。现在,把所有这些枚举类型总结到如下的表格中。
| rowidlifetime枚举类型 | 定义 |
| rowid_unsupported | 数据源不支持rowid类型 |
| rowid_valid_other | 实现依赖的生命周期 |
| rowid_valid_transaction | 生命周期至少包含事务 |
| rowid_valid_session | 生命周期至少包含会话 |
| rowid_valid_forever | 无限制生命周期 |
其中,只要没有删除行,那么rowid_valid_transaction,rowid_valid_session和rowid_valid_forever都定义为true。还要注意的是,如果一个行被删除和重新插入,那么rowid会被重新调整(这有可能在数据源中透明实现)。作为一个例子,在oracle中,如果在一个分区表上设置"enable row movement"语句,并且分区键的一个更新导致该行从一个分区移动到另一个分区,那么rowid将改变。即使在没有设置"enable row movement"标志并且"alter table table_name"发生改变时,rowid也能够改变。
resultset和callablestatement接口都被更新-都包括了一个返回javax.sql.rowid类型的方法getrowid()。
列表3展示了如何从一个resultset和callablestatement中检索rowid。
列表3.得到rowid
| //从一个resultset检索rowid的方法签名: rowid getrowid (int columnindex) rowid getrowid (string columnname) ... statement stmt = con.createstatement (); resultset rs = stmt. executequery (…); while (rs.next ()) { ... java.sql.rowid rid = rs.getrowid (1); ... } //从一个callablestatement检索rowid的方法签名: rowid getrowid (int parameterindex) rowid getrowid (string parametername) connection con; ... callablestatement cstmt = con.preparecall (…); ... cstmt.registeroutparameter (2, types.rowid); ... cstmt.executeupdate (); ... java.sql.rowid rid = cstmt.getrowid (2); |
在此,rowid可以用于唯一地参考一行并因此可被用于检索或更新行数据。当使用rowid参考来存取或更新数据时,理解生命周期的有效性是十分重要的,从而保证结果的连续性。另外,我还建议你同时使用另一个参考,例如主键,以避免在能够透明地改变rowid的情况下出现不连续的结果。
rowid值还可以被设置或更新。在一种可更新的resultset情况下,可以针对表中的一个特定的行使用updaterowid()方法来更新rowid。
另外,preparedstatement和callablestatement接口都支持setrowid()方法(其形式不一样),该方法把rowid设置为一个参数值。这个值可以用于针对表中的一个特定的行来参考数据行或更新rowid值。
由上面可知,开发者可以非常容易地设置或更新rowid;这为控制唯一的行标识符并为使这些标识符具有跨表唯一性提供了极大的灵活性。也许,跨表支持的数据源的rowid的可移植性还能够通过在这些数据源间显式地设置一致值来实现。然而,因为系统生成的rowid经常是有效的,并且可以通过透明的操作来改变rowid;所以,最好在一个应用程序中把它们用作只读属性。
六、 利用非标准供应商实现的资源
新型的jdbc api中定义了一个java.sql.wrapper接口。通过检索代理实例并使用相应的包装代理实例,这个接口提供了存取数据源供应商特定资源的能力。
这个包装接口拥有17个子接口,并且包括connection,resultset,statement,callablestatement,preparedstatement,datasource,databasemetadata和resultsetmetadata,等等。这是一种优秀的设计,因为它方便了在创建查询和"结果-设置-检索"生命周期的几乎每一个阶段使用数据源供应商特定的资源。
unwrap()方法返回实现给定接口的对象,从而允许存取供应商特定的方法。iswrapperfor()方法返回一个boolean值-如果它实现了该接口则返回true;或者,它也有可能直接或间接地成为对象的一个包装类。
作为一个例子,当使用oracle时,oracle jdbc驱动程序提供了更新批扩展-与标准jdbc批更新机制相比,它具有更好的性能且更为有效。对于早期的jdbc版本来说,这意味着要在代码中使用oracle特定的定义,例如oraclepreparedstatement。这样以来就减弱了代码的可移植性。而借助于现在新型的api,许多前面这些有效的实现都能够被包装和被暴露在标准jdbc定义中。
七、 针对驱动程序加载的服务提供者机制
在jdbc 4.0以前,在一种非托管的或独立的程序中,你必须显式地通过调用class.forname方法来加载jdbc驱动器类,如列表4所示:
列表4.class.forname方法
| class.forname ("com.driverprovider.jdbc.jdbcdriverimpl"); |
借助于jdbc 4.0,如果jdbc驱动程序供应商把他们的驱动程序打包为服务(在服务提供者机制下定义为每一种jar规范),那么drivermanager代码将通过在classpath中搜索它来隐式地装载该驱动程序。这种机制的优点在于,开发者不需要了解这种特定的驱动程序类,并且能够使用jdbc来编写较少的代码实现。另外,既然驱动程序类名不再存在于代码中,那么只改变一个名字并不要求重新编译。如果在classpath中指定了多个驱动程序,那么drivermanger将试图使用它在classpath中所找到的第一个驱动程序来创建一种连接,并且在需要时能够继续遍历下一个驱动程序。
八、 结论
在本文中,我们一同探讨了jdbc 4.0的一些新的和改进的特征。从中可以看出,许多新特征进一步便利了开发,从而提高了开发者的生产效率。另一方面,该规范并没有消除对于其它jdbc框架提供的模板化工具和高级异常处理能力的使用。然而,对该规范也存在一些批评。例如,一些人认为注释的使用会导致在代码中硬编码(而这往往导致在代码维护阶段出现问题)。究其实效,还有待于实践检验。

 闽公网安备 35060202000074号
闽公网安备 35060202000074号