摘 要 java规则引擎是一种嵌入在java程序中的组件,它的任务是把当前提交给引擎的java数据对象与加载在引擎中的业务规则进行测试和比对,激活那些符合当前数据状态下的业务规则,根据业务规则中声明的执行逻辑,触发应用程序中对应的操作。
引言
目前,java社区推动并发展了一种引人注目的新技术――java规则引擎(rule engine)。利用它就可以在应用系统中分离商业决策者的商业决策逻辑和应用开发者的技术决策,并把这些商业决策放在中心数据库或其他统一的地方,让它们能在运行时可以动态地管理和修改,从而为企业保持灵活性和竞争力提供有效的技术支持。
规则引擎的原理
1、基于规则的专家系统(rbes)简介
java规则引擎起源于基于规则的专家系统,而基于规则的专家系统又是专家系统的其中一个分支。专家系统属于人工智能的范畴,它模仿人类的推理方式,使用试探性的方法进行推理,并使用人类能理解的术语解释和证明它的推理结论。为了更深入地了解java规则引擎,下面简要地介绍基于规则的专家系统。rbes包括三部分:rule base(knowledge base)、working memory(fact base)和inference engine。它们的结构如下系统所示:
如图1所示,推理引擎包括三部分:模式匹配器(pattern matcher)、议程(agenda)和执行引擎(execution engine)。推理引擎通过决定哪些规则满足事实或目标,并授予规则优先级,满足事实或目标的规则被加入议程。模式匹配器决定选择执行哪个规则,何时执行规则;议程管理模式匹配器挑选出来的规则的执行次序;执行引擎负责执行规则和其他动作。
和人类的思维相对应,推理引擎存在两者推理方式:演绎法(forward-chaining)和归纳法(backward-chaining)。演绎法从一个初始的事实出发,不断地应用规则得出结论(或执行指定的动作)。而归纳法则是根据假设,不断地寻找符合假设的事实。rete算法是目前效率最高的一个forward-chaining推理算法,许多java规则引擎都是基于rete算法来进行推理计算的。
推理引擎的推理步骤如下:
(1)将初始数据(fact)输入working memory。
(2)使用pattern matcher比较规则库(rule base)中的规则(rule)和数据(fact)。
(3)如果执行规则存在冲突(conflict),即同时激活了多个规则,将冲突的规则放入冲突集合。
(4)解决冲突,将激活的规则按顺序放入agenda。
(5)使用执行引擎执行agenda中的规则。重复步骤2至5,直到执行完毕所有agenda中的规则。
上述即是规则引擎的原始架构,java规则引擎就是从这一原始架构演变而来的。
2、规则引擎相关构件
规则引擎是一种根据规则中包含的指定过滤条件,判断其能否匹配运行时刻的实时条件来执行规则中所规定的动作的引擎。与规则引擎相关的有四个基本概念,为更好地理解规则引擎的工作原理,下面将对这些概念进行逐一介绍。
1)信息元(information unit)
信息元是规则引擎的基本建筑块,它是一个包含了特定事件的所有信息的对象。这些信息包括:消息、产生事件的应用程序标识、事件产生事件、信息元类型、相关规则集、通用方法、通用属性以及一些系统相关信息等等。
2)信息服务(information services)
信息服务产生信息元对象。每个信息服务产生它自己类型相对应的信息元对象。即特定信息服务根据信息元所产生每个信息元对象有相同的格式,但可以有不同的属性和规则集。需要注意的是,在一台机器上可以运行许多不同的信息服务,还可以运行同一信息服务的不同实例。但无论如何,每个信息服务只产生它自己类型相对应的信息元。
3)规则集(rule set)
顾名思义,规则集就是许多规则的集合。每条规则包含一个条件过滤器和多个动作。一个条件过滤器可以包含多个过滤条件。条件过滤器是多个布尔表达式的组合,其组合结果仍然是一个布尔类型的。在程序运行时,动作将会在条件过滤器值为真的情况下执行。除了一般的执行动作,还有三类比较特别的动作,它们分别是:放弃动作(discard action)、包含动作(include action)和使信息元对象内容持久化的动作。前两种动作类型的区别将在2.3规则引擎工作机制小节介绍。
4)队列管理器(queue manager)
队列管理器用来管理来自不同信息服务的信息元对象的队列。
下面将研究规则引擎的这些相关构件是如何协同工作的。
如图2所示,处理过程分为四个阶段进行:信息服务接受事件并将其转化为信息元,然后这些信息元被传给队列管理器,最后规则引擎接收这些信息元并应用它们自身携带的规则加以执行,直到队列管理器中不再有信息元。
3、规则引擎的工作机制
下面专门研究规则引擎的内部处理过程。如图3所示,规则引擎从队列管理器中依次接收信息元,然后依规则的定义顺序检查信息元所带规则集中的规则。如图所示,规则引擎检查第一个规则并对其条件过滤器求值,如果值为假,所有与此规则相关的动作皆被忽略并继续执行下一条规则。如果第二条规则的过滤器值为真,所有与此规则相关的动作皆依定义顺序执行,执行完毕继续下一条规则。该信息元中的所有规则执行完毕后,信息元将被销毁,然后从队列管理器接收下一个信息元。在这个过程中并未考虑两个特殊动作:放弃动作(discard action)和包含动作(include action)。放弃动作如果被执行,将会跳过其所在信息元中接下来的所有规则,并销毁所在信息元,规则引擎继续接收队列管理器中的下一个信息元。包含动作其实就是动作中包含其它现存规则集的动作。包含动作如果被执行,规则引擎将暂停并进入被包含的规则集,执行完毕后,规则引擎还会返回原来暂停的地方继续执行。这一过程将递归进行。
引言
目前,java社区推动并发展了一种引人注目的新技术――java规则引擎(rule engine)。利用它就可以在应用系统中分离商业决策者的商业决策逻辑和应用开发者的技术决策,并把这些商业决策放在中心数据库或其他统一的地方,让它们能在运行时可以动态地管理和修改,从而为企业保持灵活性和竞争力提供有效的技术支持。
规则引擎的原理
1、基于规则的专家系统(rbes)简介
java规则引擎起源于基于规则的专家系统,而基于规则的专家系统又是专家系统的其中一个分支。专家系统属于人工智能的范畴,它模仿人类的推理方式,使用试探性的方法进行推理,并使用人类能理解的术语解释和证明它的推理结论。为了更深入地了解java规则引擎,下面简要地介绍基于规则的专家系统。rbes包括三部分:rule base(knowledge base)、working memory(fact base)和inference engine。它们的结构如下系统所示:
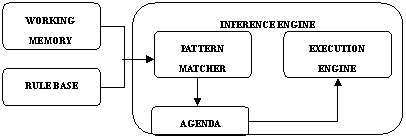 图1 基于规则的专家系统构成 |
如图1所示,推理引擎包括三部分:模式匹配器(pattern matcher)、议程(agenda)和执行引擎(execution engine)。推理引擎通过决定哪些规则满足事实或目标,并授予规则优先级,满足事实或目标的规则被加入议程。模式匹配器决定选择执行哪个规则,何时执行规则;议程管理模式匹配器挑选出来的规则的执行次序;执行引擎负责执行规则和其他动作。
和人类的思维相对应,推理引擎存在两者推理方式:演绎法(forward-chaining)和归纳法(backward-chaining)。演绎法从一个初始的事实出发,不断地应用规则得出结论(或执行指定的动作)。而归纳法则是根据假设,不断地寻找符合假设的事实。rete算法是目前效率最高的一个forward-chaining推理算法,许多java规则引擎都是基于rete算法来进行推理计算的。
推理引擎的推理步骤如下:
(1)将初始数据(fact)输入working memory。
(2)使用pattern matcher比较规则库(rule base)中的规则(rule)和数据(fact)。
(3)如果执行规则存在冲突(conflict),即同时激活了多个规则,将冲突的规则放入冲突集合。
(4)解决冲突,将激活的规则按顺序放入agenda。
(5)使用执行引擎执行agenda中的规则。重复步骤2至5,直到执行完毕所有agenda中的规则。
上述即是规则引擎的原始架构,java规则引擎就是从这一原始架构演变而来的。
2、规则引擎相关构件
规则引擎是一种根据规则中包含的指定过滤条件,判断其能否匹配运行时刻的实时条件来执行规则中所规定的动作的引擎。与规则引擎相关的有四个基本概念,为更好地理解规则引擎的工作原理,下面将对这些概念进行逐一介绍。
1)信息元(information unit)
信息元是规则引擎的基本建筑块,它是一个包含了特定事件的所有信息的对象。这些信息包括:消息、产生事件的应用程序标识、事件产生事件、信息元类型、相关规则集、通用方法、通用属性以及一些系统相关信息等等。
2)信息服务(information services)
信息服务产生信息元对象。每个信息服务产生它自己类型相对应的信息元对象。即特定信息服务根据信息元所产生每个信息元对象有相同的格式,但可以有不同的属性和规则集。需要注意的是,在一台机器上可以运行许多不同的信息服务,还可以运行同一信息服务的不同实例。但无论如何,每个信息服务只产生它自己类型相对应的信息元。
3)规则集(rule set)
顾名思义,规则集就是许多规则的集合。每条规则包含一个条件过滤器和多个动作。一个条件过滤器可以包含多个过滤条件。条件过滤器是多个布尔表达式的组合,其组合结果仍然是一个布尔类型的。在程序运行时,动作将会在条件过滤器值为真的情况下执行。除了一般的执行动作,还有三类比较特别的动作,它们分别是:放弃动作(discard action)、包含动作(include action)和使信息元对象内容持久化的动作。前两种动作类型的区别将在2.3规则引擎工作机制小节介绍。
4)队列管理器(queue manager)
队列管理器用来管理来自不同信息服务的信息元对象的队列。
下面将研究规则引擎的这些相关构件是如何协同工作的。
如图2所示,处理过程分为四个阶段进行:信息服务接受事件并将其转化为信息元,然后这些信息元被传给队列管理器,最后规则引擎接收这些信息元并应用它们自身携带的规则加以执行,直到队列管理器中不再有信息元。
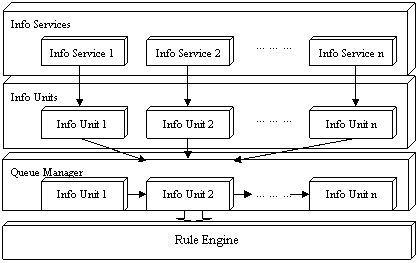 图2 处理过程协作图 |
3、规则引擎的工作机制
下面专门研究规则引擎的内部处理过程。如图3所示,规则引擎从队列管理器中依次接收信息元,然后依规则的定义顺序检查信息元所带规则集中的规则。如图所示,规则引擎检查第一个规则并对其条件过滤器求值,如果值为假,所有与此规则相关的动作皆被忽略并继续执行下一条规则。如果第二条规则的过滤器值为真,所有与此规则相关的动作皆依定义顺序执行,执行完毕继续下一条规则。该信息元中的所有规则执行完毕后,信息元将被销毁,然后从队列管理器接收下一个信息元。在这个过程中并未考虑两个特殊动作:放弃动作(discard action)和包含动作(include action)。放弃动作如果被执行,将会跳过其所在信息元中接下来的所有规则,并销毁所在信息元,规则引擎继续接收队列管理器中的下一个信息元。包含动作其实就是动作中包含其它现存规则集的动作。包含动作如果被执行,规则引擎将暂停并进入被包含的规则集,执行完毕后,规则引擎还会返回原来暂停的地方继续执行。这一过程将递归进行。
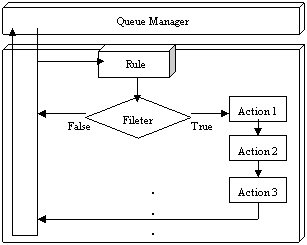
图3 规则引擎工作机制
java规则引擎的工作机制与上述规则引擎机制十分类似,只不过对上述概念进行了重新包装组合。java规则引擎对提交给引擎的java数据对象进行检索,根据这些对象的当前属性值和它们之间的关系,从加载到引擎的规则集中发现符合条件的规则,创建这些规则的执行实例。这些实例将在引擎接到执行指令时、依照某种优先序依次执行。一般来讲,java规则引擎内部由下面几个部分构成:工作内存(working memory)即工作区,用于存放被引擎引用的数据对象集合;规则执行队列,用于存放被激活的规则执行实例;静态规则区,用于存放所有被加载的业务规则,这些规则将按照某种数据结构组织,当工作区中的数据发生改变后,引擎需要迅速根据工作区中的对象现状,调整规则执行队列中的规则执行实例。java规则引擎的结构示意图如图4所示。

扫描关注微信公众号 © 2005-2021 漳州市福佳网络科技有限公司 版权所有 闽ICP备09012882号-3
|
 闽公网安备 35060202000074号
闽公网安备 35060202000074号