目前,java社区推动并发展了一种引人注目的新技术――java规则引擎(rule engine)。利用它就可以在应用系统中分离商业决策者的商业决策逻辑和应用开发者的技术决策,并把这些商业决策放在中心数据库或其他统一的地方,让它们能在运行时可以动态地管理和修改,从而为企业保持灵活性和竞争力提供有效的技术支持。
规则引擎的原理
1、基于规则的专家系统(rbes)简介
java规则引擎起源于基于规则的专家系统,而基于规则的专家系统又是专家系统的其中一个分支。专家系统属于人工智能的范畴,它模仿人类的推理方式,使用试探性的方法进行推理,并使用人类能理解的术语解释和证明它的推理结论。为了更深入地了解java规则引擎,下面简要地介绍基于规则的专家系统。rbes包括三部分:rule base(knowledge base)、working memory(fact base)和inference engine。它们的结构如下系统所示:
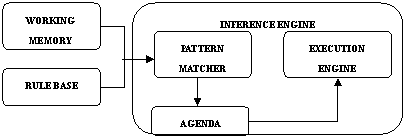
图1 基于规则的专家系统构成
如图1所示,推理引擎包括三部分:模式匹配器(pattern matcher)、议程(agenda)和执行引擎(execution engine)。推理引擎通过决定哪些规则满足事实或目标,并授予规则优先级,满足事实或目标的规则被加入议程。模式匹配器决定选择执行哪个规则,何时执行规则;议程管理模式匹配器挑选出来的规则的执行次序;执行引擎负责执行规则和其他动作。
和人类的思维相对应,推理引擎存在两者推理方式:演绎法(forward-chaining)和归纳法(backward-chaining)。演绎法从一个初始的事实出发,不断地应用规则得出结论(或执行指定的动作)。而归纳法则是根据假设,不断地寻找符合假设的事实。rete算法是目前效率最高的一个forward-chaining推理算法,许多java规则引擎都是基于rete算法来进行推理计算的。
推理引擎的推理步骤如下:
(1)将初始数据(fact)输入working memory。
(2)使用pattern matcher比较规则库(rule base)中的规则(rule)和数据(fact)。
(3)如果执行规则存在冲突(conflict),即同时激活了多个规则,将冲突的规则放入冲突集合。
(4)解决冲突,将激活的规则按顺序放入agenda。
(5)使用执行引擎执行agenda中的规则。重复步骤2至5,直到执行完毕所有agenda中的规则。
上述即是规则引擎的原始架构,java规则引擎就是从这一原始架构演变而来的。
2、规则引擎相关构件
规则引擎是一种根据规则中包含的指定过滤条件,判断其能否匹配运行时刻的实时条件来执行规则中所规定的动作的引擎。与规则引擎相关的有四个基本概念,为更好地理解规则引擎的工作原理,下面将对这些概念进行逐一介绍。
1)信息元(information unit)
信息元是规则引擎的基本建筑块,它是一个包含了特定事件的所有信息的对象。这些信息包括:消息、产生事件的应用程序标识、事件产生事件、信息元类型、相关规则集、通用方法、通用属性以及一些系统相关信息等等。
2)信息服务(information services)
信息服务产生信息元对象。每个信息服务产生它自己类型相对应的信息元对象。即特定信息服务根据信息元所产生每个信息元对象有相同的格式,但可以有不同的属性和规则集。需要注意的是,在一台机器上可以运行许多不同的信息服务,还可以运行同一信息服务的不同实例。但无论如何,每个信息服务只产生它自己类型相对应的信息元。
3)规则集(rule set)
顾名思义,规则集就是许多规则的集合。每条规则包含一个条件过滤器和多个动作。一个条件过滤器可以包含多个过滤条件。条件过滤器是多个布尔表达式的组合,其组合结果仍然是一个布尔类型的。在程序运行时,动作将会在条件过滤器值为真的情况下执行。除了一般的执行动作,还有三类比较特别的动作,它们分别是:放弃动作(discard action)、包含动作(include action)和使信息元对象内容持久化的动作。前两种动作类型的区别将在2.3规则引擎工作机制小节介绍。
4)队列管理器(queue manager)
队列管理器用来管理来自不同信息服务的信息元对象的队列。
下面将研究规则引擎的这些相关构件是如何协同工作的。
如图2所示,处理过程分为四个阶段进行:信息服务接受事件并将其转化为信息元,然后这些信息元被传给队列管理器,最后规则引擎接收这些信息元并应用它们自身携带的规则加以执行,直到队列管理器中不再有信息元。
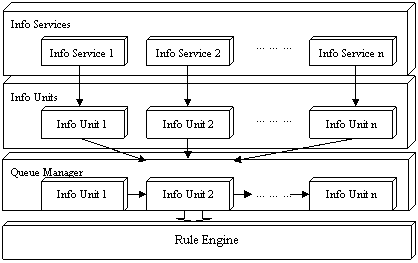
图2 处理过程协作图
3、规则引擎的工作机制
下面专门研究规则引擎的内部处理过程。如图3所示,规则引擎从队列管理器中依次接收信息元,然后依规则的定义顺序检查信息元所带规则集中的规则。如图所示,规则引擎检查第一个规则并对其条件过滤器求值,如果值为假,所有与此规则相关的动作皆被忽略并继续执行下一条规则。如果第二条规则的过滤器值为真,所有与此规则相关的动作皆依定义顺序执行,执行完毕继续下一条规则。该信息元中的所有规则执行完毕后,信息元将被销毁,然后从队列管理器接收下一个信息元。在这个过程中并未考虑两个特殊动作:放弃动作(discard action)和包含动作(include action)。放弃动作如果被执行,将会跳过其所在信息元中接下来的所有规则,并销毁所在信息元,规则引擎继续接收队列管理器中的下一个信息元。包含动作其实就是动作中包含其它现存规则集的动作。包含动作如果被执行,规则引擎将暂停并进入被包含的规则集,执行完毕后,规则引擎还会返回原来暂停的地方继续执行。这一过程将递归进行。
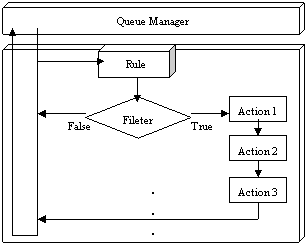
图3 规则引擎工作机制
java规则引擎的工作机制与上述规则引擎机制十分类似,只不过对上述概念进行了重新包装组合。java规则引擎对提交给引擎的java数据对象进行检索,根据这些对象的当前属性值和它们之间的关系,从加载到引擎的规则集中发现符合条件的规则,创建这些规则的执行实例。这些实例将在引擎接到执行指令时、依照某种优先序依次执行。一般来讲,java规则引擎内部由下面几个部分构成:工作内存(working memory)即工作区,用于存放被引擎引用的数据对象集合;规则执行队列,用于存放被激活的规则执行实例;静态规则区,用于存放所有被加载的业务规则,这些规则将按照某种数据结构组织,当工作区中的数据发生改变后,引擎需要迅速根据工作区中的对象现状,调整规则执行队列中的规则执行实例。java规则引擎的结构示意图如图4所示。
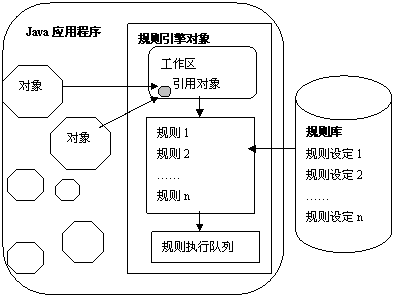
图4 java规则引擎工作机制
当引擎执行时,会根据规则执行队列中的优先顺序逐条执行规则执行实例,由于规则的执行部分可能会改变工作区的数据对象,从而会使队列中的某些规则执行实例因为条件改变而失效,必须从队列中撤销,也可能会激活原来不满足条件的规则,生成新的规则执行实例进入队列。于是就产生了一种“动态”的规则执行链,形成规则的推理机制。这种规则的“链式”反应完全是由工作区中的数据驱动的。
任何一个规则引擎都需要很好地解决规则的推理机制和规则条件匹配的效率问题。规则条件匹配的效率决定了引擎的性能,引擎需要迅速测试工作区中的数据对象,从加载的规则集中发现符合条件的规则,生成规则执行实例。1982年美国卡耐基?梅隆大学的charles l. forgy发明了一种叫rete算法,很好地解决了这方面的问题。目前世界顶尖的商用业务规则引擎产品基本上都使用rete算法。
java规则引擎api――jsr-94
为了使规则引擎技术标准化,java社区制定了java规则引擎api(jsr94)规范。它为java平台访问规则引擎定义了一些简单的api。
java规则引擎api在javax.rules包中定义,是访问规则引擎的标准企业级api。java规则引擎api允许客户程序使用统一的方式和不同厂商的规则引擎产品交互,就如同使用jdbc编写独立于厂商访问不同的数据库产品一样。java规则引擎api包括创建和管理规则集合的机制,在工作区中添加,删除和修改对象的机制,以及初始化,重置和执行规则引擎的机制。
1、java规则引擎api体系结构
java规则引擎api主要由两大类api组成: 规则管理api(the rules administrator api)和运行时客户api(the runtime client api)。
1)规则管理api
规则管理api在javax.rules.admin中定义,包含装载规则以及与规则对应的动作(执行集 execution sets)以及实例化规则引擎。规则可以从外部资源中装载,比如uri,input streams, xml streams和readers等等。同时规则管理api还提供了注册和取消注册执行集以及对执行集进行维护的机制。使用admin包定义规则有助于对客户访问运行规则进行控制管理,它通过在执行集上定义许可权使得未经授权的用户无法访问受控规则。
规则管理api使用类ruleserviceprovider来获得规则管理器(ruleadministrator)接口的实例。该接口提供方法注册和取消注册执行集。规则管理器提供了本地和远程的ruleexecutionsetprovider,它负责创建规则执行集(ruleexecutionset)。规则执行集可以从如xml streams, binary streams等来源中创建。这些数据来源及其内容经汇集和序列化后传送到远程的运行规则引擎的服务器上。在大多数应用程序中,远程规则引擎或远程规则数据来源的情况并不多。为了避免这些情况中的网络开销,api规定了可以从运行在同一jvm中规则库中读取数据的本地ruleexecutionsetprovider。规则执行集接口除了拥有能够获得有关规则执行集的方法,还有能够检索在规则执行集中定义的所有规则对象。这使得客户能够知道规则集中的规则对象并且按照自己需要来使用它们。
2)运行时客户api
运行时api在javax.rules包中定义,为规则引擎用户运行规则获得结果提供了类和方法。运行时客户只能访问那些使用规则管理api注册过的规则,运行时api帮助用户获得规则会话,并在这个会话中执行规则。
运行时api提供了对厂商规则引擎api的访问方法,这类似于jdbc。类ruleserviceprovider提供了对具体规则引擎实现的运行时和管理api的访问,规则引擎厂商通过该类将其规则引擎实现提供给客户,并获得ruleserviceprovider唯一标识规则引擎的url。此url的标准用法是使用类似于“com.mycompany.myrulesengine.rules.ruleserviceprovider”这样的internet域名空间,这保证了访问url的唯一性。类ruleserviceprovider内部实现了规则管理和运行时访问所需的接口。所有的ruleserviceprovider要想被客户所访问都必须用ruleserviceprovidermanager进行注册,注册方式类似于jdbc api的drivermanager和driver。
运行时接口是运行时api的关键部分。运行时接口提供了用于创建规则会话(rulesession)的方法,规则会话是用来运行规则的。运行时api同时也提供了访问在service provider注册过的所有规则执行集(ruleexecutionsets)。规则会话接口定义了客户使用的会话的类型,客户根据自己运行规则的方式可以选择使用有状态会话或者无状态会话。无状态会话的工作方式就像一个无状态会话bean。客户可以发送单个输入对象或一列对象来获得输出对象。当客户需要一个与规则引擎间的专用会话时,有状态会话就很有用。输入的对象通过addobject() 方法可以加入到会话当中。同一个会话当中可以加入多个对象。对话中已有对象可以通过使用updateobject()方法得到更新。只要客户与规则引擎间的会话依然存在,会话中的对象就不会丢失。
ruleexecutionsetmetadata接口提供给客户让其查找规则执行集的元数据(metadata)。元数据通过规则会话接口(rulesession interface)提供给用户。
2、java规则引擎api安全问题
规则引擎api将管理api和运行时api加以分开,从而为这些包提供了较好粒度的安全控制。规则引擎api并没有提供明显的安全机制,它可以和j2ee规范中定义的标准安全api联合使用。安全可以由以下机制提供,如java 认证和授权服务 (jaas),java加密扩展(jce),java安全套接字扩展(jsse),或者其它定制的安全api。使用jaas可以定义规则执行集的许可权限,从而只有授权用户才能访问。
3、异常与日志
规则引擎api定义了javax.rules.ruleexception作为规则引擎异常层次的根类。所有其它异常都继承于这个根类。规则引擎中定义的异常都是受控制的异常(checked exceptions),所以捕获异常的任务就交给了规则引擎。规则引擎api没有提供明确的日志机制,但是它建议将java logging api用于规则引擎api。
jsr 94 为规则引擎提供了公用标准api,仅仅为实现规则管理api和运行时api提供了指导规范,并没有提供规则和动作该如何定义以及该用什么语言定义规则,也没有为规则引擎如何读和评价规则提供技术性指导。
结束语
规则引擎技术为管理多变的业务逻辑提供了一种解决方案。规则引擎既可以管理应用层的业务逻辑又可以使表示层的页面流程可订制。这就给软件架构师设计大型信息系统提供了一项新的选择。而java规则引擎在java社区制定标准规范以后必将获得更大发展。

 闽公网安备 35060202000074号
闽公网安备 35060202000074号